
AI agents vs generic AI writers: what SMBs need in 2026
Compare AI agents vs AI writers — how RAG-driven learning loops, governance, and orchestration affect pipeline, leads, and brand safety for SMBs.
If your team’s goal is a healthier pipeline, the approach you choose matters more than the model you pick. Here’s the short version: agentic systems learn and improve; generic AI writers mostly don’t. That difference shows up in fidelity, brand safety, and ultimately in qualified leads.
TL;DR verdict: Choose agentic platforms when you need closed-loop learning and measurable pipeline lift; choose generic AI writers for low-cost drafting and occasional copy. For governance-sensitive teams, agents win due to approvals, audit trails, and provenance support.
How we compared
We evaluated AI agents vs AI writers across ten dimensions tied to SMB outcomes: learning loops, governance and approvals, planning and orchestration, autonomy and tool use, evidence grounding and knowledge bases, human-in-the-loop experience, outcome metrics and attribution, integrations and extensibility, velocity and throughput, and cost and TCO. Evidence draws on enterprise explainers and vendor documentation: for example, IBM’s guidance on RAG evaluation metrics, Google Cloud’s retrieval optimization practices, Microsoft’s agent framework patterns, Red Hat’s outlook on agentic adoption, GA4 attribution updates, and Salesforce’s GA4 connector references. We note where facts are volatile and keep claims conservative.
Side-by-side comparison matrix
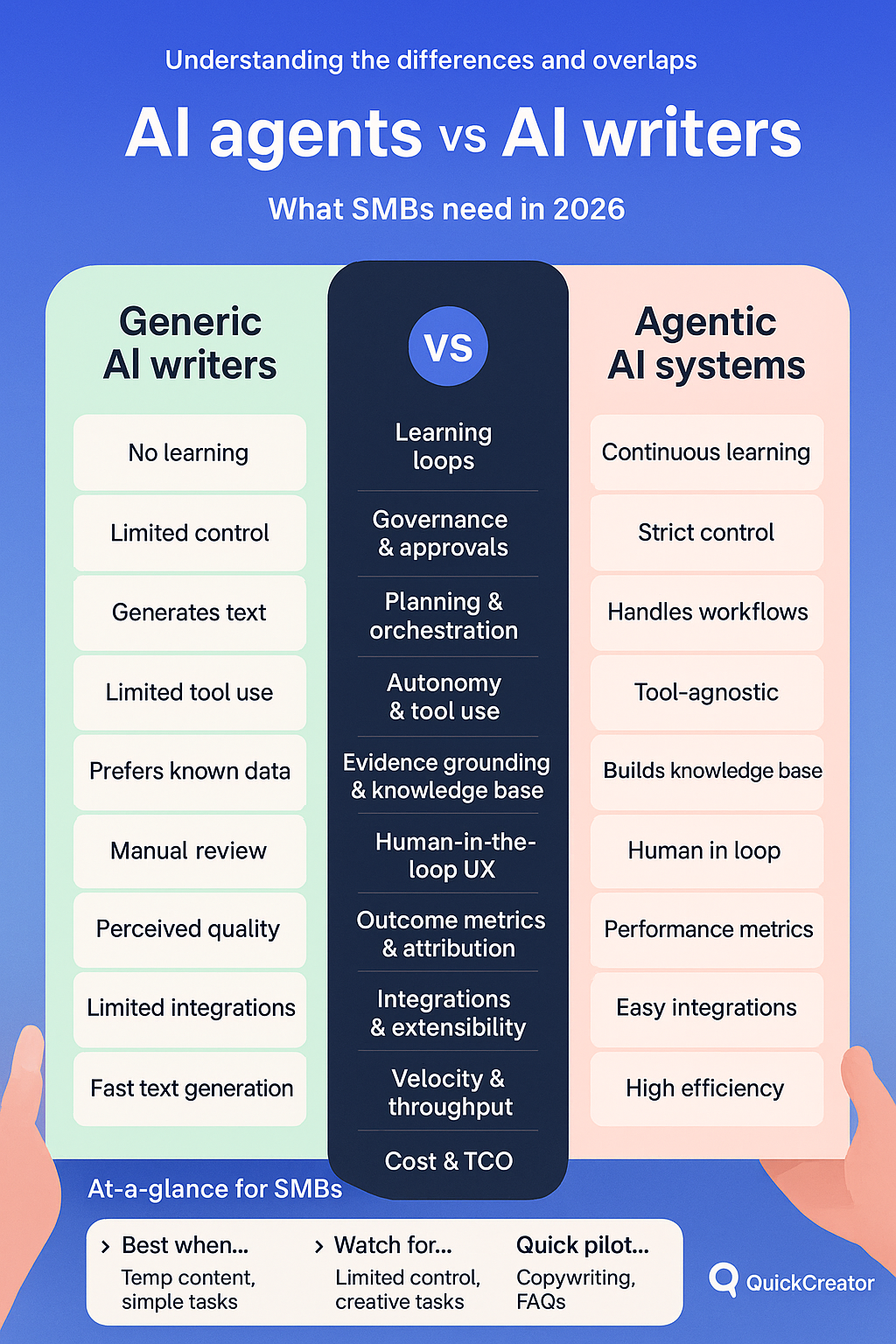
Dimension | Generic AI writers | Agentic AI systems |
|---|---|---|
Learning loops | Little to no iterative improvement; prompts adjusted manually | Built for retrieval grounding, evaluation metrics, and human review to iteratively improve |
Governance and approvals | Ad hoc editing, minimal workflow controls | Role-based approvals, audit trails, and provenance labeling are commonly supported |
Planning and orchestration | Single-pass generation, user coordinates steps | Planner–orchestrator–executor patterns coordinate multi-step workflows |
Autonomy and tool use | Limited function use; mostly text-only | Function calling, API tools, bounded autonomy modes with guardrails |
Evidence grounding and KB | Weak citation support; copy-paste sources | Vector search and citation binding against private knowledge bases |
Human-in-the-loop UX | Edit-in-doc experience | Structured review queues, rubric scoring, staged approvals |
Outcome metrics and attribution | Page analytics with weak CRM tie-in | GA4 and CRM integration for assisted revenue visibility |
Integrations and extensibility | Browser extensions and a few apps | Broad CMS, CRM, analytics, webhooks, SDKs to close the loop |
Velocity and throughput | Fast single drafts, manual orchestration | Parallelism, retries, scheduling for sustained multi-channel output |
Cost and TCO | Low per-seat pricing, minimal setup | Higher platform complexity; at scale, automation can lower TCO per asset |
Learning loops and quality assurance hero
Here’s the deal: the biggest separator in AI agents vs AI writers is whether the system gets steadily better. In agentic setups, learning loops tie three elements together: retrieval grounding, structured feedback, and evaluation. Teams monitor faithfulness to sources and context precision or recall, then iterate. IBM details how to score grounded answers with metrics like faithfulness and contextual recall in its RAG evaluation guidance, while Google Cloud explains how better retrieval and re-ranking raise answer quality. See the principles in IBM’s overview of RAG result evaluation and Google Cloud’s article on optimizing retrieval for RAG.
Why it matters for pipeline: faithful, on-brand assets reduce friction for buyers and sales. When content accurately reflects product facts and customer language, landing pages convert more, emails nurture better, and sales enablement stays consistent. Most generic writers can’t sustain that improvement across many assets because they lack retrieval grounding, explicit feedback capture, and evaluative gates. Agentic systems, by contrast, can bind citations to a private knowledge base, collect reviewer scores, log changes, and run another pass to fix issues before publish.
Practical targets: many production teams aim for strong faithfulness and recall scores and store evidence links alongside outputs. Over time, they update prompts, retrieval settings, and knowledge content to address recurring errors. The output feels steadier—fewer jarring transitions, tighter claims, clearer references—and that stability tends to correlate with better lead quality.
References for practice: IBM’s guidance on RAG result evaluation outlines groundedness scoring, and Google Cloud’s retrieval optimization shows how chunking and re-ranking improve context quality.
Governance, safety, and approvals without drama
A common and healthy objection is that “AI will go off-brand or unsafe without tight controls.” Agentic platforms address this by design. You can enforce role-based approvals, restrict who can touch which knowledge, capture audit logs for every step, and label outputs for provenance or watermarking. Enterprise governance references point to these patterns as table stakes for scaling safely. For example, the ITU’s discussion of AI watermarking highlights provenance techniques, while enterprise governance guides show how RBAC, auditability, and policy checks reduce exposure.
Contrast this with generic writers: you can always copy outputs into a doc and run manual review, but you won’t get a built-in trail of who approved what or automatic policy checks before publish. At small volumes, that might be fine. At scale, it strains.
What good looks like:
Role-based stages that separate drafting, editing, legal, and publish controls with audit logs.
Policy gates for banned terms, disclosure requirements, or claim thresholds.
Provenance labels so downstream systems know what was AI-assisted.
If you operate in regulated or brand-sensitive categories, those three controls turn risk from a blocker into a manageable process.
Planning and orchestration with real autonomy
Agentic systems convert strategy into execution. Instead of nudging a writer with prompt after prompt, a planner–orchestrator–executor loop decomposes the goal, sequences steps, and calls the right tools. Microsoft’s agent framework coverage outlines patterns like sequential and concurrent execution, manager-led agent groups, and handoffs. Red Hat’s outlook suggests rapid enterprise adoption of these workflows as teams look beyond single-model prompting.
For SMB marketers, orchestration matters when one asset must turn into many: blog to email, LinkedIn post, and CMS page—with approvals and analytics wired in. An agentic system can schedule that cascade and pause for review at the right times. Tool use is not “let it run wild”; it’s bounded autonomy with guardrails, retries, and visibility.
If your goal is multi-channel consistency, orchestration is where agents shine. A compact example: a distribution agent that takes a final, approved article, formats variations per channel, schedules posts, and logs published URLs—without you pasting between tabs.
Outcome metrics and attribution for pipeline
If the narrative doesn’t land in your CRM, it didn’t happen. Strong agentic stacks wire content performance into GA4 and CRM so you can see assisted influence on MQLs, SQLs, and revenue. GA4’s attribution changes are well documented, and organizations often import offline CRM events so assisted paths show up in analytics. Salesforce has referenced a GA4 connector in release notes, and many teams push CRM conversions into GA4 or join datasets in BigQuery to get a realistic read on influence.
Generic writers rarely offer built-in attribution. That doesn’t make attribution impossible, but it pushes more manual effort onto your ops stack.
Cost and TCO note: yes, agentic platforms can be pricier upfront. But with higher throughput, reuse, and fewer corrective edits, the cost per effective asset can drop at scale. Plan for model usage, integration time, and reviewer hours in your 12‑month estimate—and measure time-to-first-value.
AI agents vs AI writers for pipeline impact
Put simply, agentic systems usually provide the closed loop you need to raise content quality and prove influence on pipeline. Generic AI writers are better for quick drafts when cost and simplicity trump governance and measurement. If your priority is qualified leads and assisted revenue you can show in dashboards, agents fit the job.
Best for who scenarios
Pipeline-first teams that need measurable assisted revenue with minimal risk: choose agentic platforms with RAG, review gates, and CRM attribution.
Governance-first or brand-sensitive teams: choose agentic platforms with RBAC, audit logging, and provenance labeling.
Velocity-first teams with low integration appetite: choose generic AI writers for rapid drafting and accept manual oversight.
DIY startups on tight budgets: choose generic AI writers for ad hoc copy and keep a light review process.
Multi-channel marketers: choose agents for planner–orchestrator–executor workflows and scheduled distribution.
Also consider QuickCreator
If you are exploring agentic approaches, you can review a multi-agent model such as QuickCreator. Its Distribution Agent focuses on orchestrated, cross-channel publishing, which is useful for turning one approved asset into many placements. Learn more via the Distribution Agent overview at QuickCreator Distribution Agent. For grounding content in your own facts, see the knowledge base introduction at What is an AI Knowledge Base. Mentioned here solely as a practical example; evaluate fit against your governance and attribution needs.
FAQ
How do learning loops improve content quality
Learning loops combine retrieval from a trusted knowledge base, structured human feedback, and evaluation metrics. Over iterations, they reduce hallucinations, tighten claims, and keep tone consistent. IBM’s RAG evaluation guidance and Google Cloud’s retrieval optimization outline the mechanics and metrics behind these gains.
Will agents go off-brand without tight controls
Not if you design governance up front. Use role-based approvals, audit trails, and provenance labeling to keep outputs reviewable and compliant. These are standard enterprise patterns and are increasingly supported within agentic platforms and adjacent identity or policy layers.
Do agents require complex integrations
They do require more setup than a generic writer, but the payoff is closed-loop measurement and automation. Start small: wire GA4 and CRM for assisted revenue attribution, then add orchestration for distribution and review gates.
When should we stick with generic AI writers
If you only need occasional drafts, have strong manual QA, and don’t need integrated attribution, a generic writer is faster and cheaper to deploy. Reassess when content volume rises or brand safety becomes a constraint.
Next steps to validate in your stack
Pick one pipeline-relevant workflow, such as a landing page plus two follow-up emails, and define success metrics.
Implement a minimal learning loop: seed a knowledge base, add a review rubric, and track faithfulness and context recall alongside conversions.
Connect GA4 and CRM to capture assisted influence; compare an agentic workflow against your current writer process for 4–6 weeks.
If the agentic loop lifts quality scores and assisted conversions, expand to more assets. If not, adjust retrieval, feedback criteria, or review gates and retest.
Sources for further reading
See groundedness scoring in the discussion of RAG result evaluation from IBM’s RAG evaluation guidance.
Learn retrieval optimization techniques from Google Cloud’s article on optimizing retrieval for RAG.
Explore orchestration patterns in Microsoft’s coverage of its agent framework.
Review the enterprise adoption outlook in Red Hat’s agentic AI topic and executive guidance.
Understand attribution changes via this overview of GA4 attribution updates.
Note the CRM analytics tie-in in Salesforce’s reference to a GA4 connector in release notes.