Strategies for Auditing Your Brand's Visibility in LLMs: The 2025 Advanced Guide

Introduction: LLM Visibility—The New Digital Brand Priority
Large Language Models (LLMs) like ChatGPT, Gemini, Claude, and Perplexity now drive millions of AI-generated answers and recommendations across search, assistants, and digital PR channels. For digital marketers and brand leaders, auditing visibility within these generative systems has rapidly become as essential as traditional SEO or paid search.
Why now? Research from DesignRush and the LLMO White Paper highlights both the opportunity and risk: brands cited or recommended by LLMs earn exponential share-of-voice, authority, and even direct referral traffic—while invisible brands lose digital mindshare, sentiment, and revenue. Yet, few organizations operate a systematic, data-led audit process.
This advanced guide delivers a step-by-step blueprint to audit (and ultimately improve) your brand’s LLM performance, with authoritative strategies, real-world metrics, and a downloadable audit checklist for implementation.
1. Establish a Foundation: Identify Priority LLMs and Brand Touchpoints
What & Why: Not all LLMs equally impact your brand’s industry or audience. Define which models (e.g., OpenAI’s ChatGPT, Google Gemini, Anthropic Claude, Perplexity, Bing Copilot) and knowledge sources shape your category’s conversations.
How:
Map digital touchpoints: Document where prospects and customers interface with LLMs—search, in-app assistants, vertical AI tools.
List key queries: Determine high-value brand and product terms, competitor sets, and category-defining prompts likely asked of these models (e.g., “Best project management SaaS in 2025?”).
Align with business impact: Prioritize models by traffic influence or platform importance in your sector. DesignRush’s LLM tool trends are a strong starting point.
Impact: Establishes clear audit scope and ensures strategic focus—eliminating wasted effort on irrelevant or low-leverage models.
2. Build & Benchmark a Prompt Set for LLM Audits
What & Why: Auditing starts with the right prompts: model inputs that reflect customer intent and competitive context. According to the LLMO audit framework, a robust and repeatable prompt set underpins every reliable audit.
How:
Design scenario-based prompts: Cover brand, competitor, and generic category queries.
Test for variability: Run prompts at different times and user profiles to detect response fluctuation.
Document wordings: Standardize prompt phrasing to ensure data comparability.
Template resource: Download a sample LLM audit prompt template (multiple competitors and independent resources available).
Impact: Removes audit subjectivity, creates a repeatable baseline, and reveals both strengths and blind spots in LLM perception.
3. Use Multi-Model LLM Audit Tools for Automated Tracking
What & Why: Manual querying is impractical and error-prone at scale. Next-generation audit platforms like Peec AI, Profound, Otterly AI, and Scrunch AI offer real-time, cross-model audit capabilities—tracking brand mentions, sentiment, and competitor profiles across the major LLMs.
How:
Select an appropriate platform: Compare Peec AI (best for daily, multi-LLM visibility alerts), Profound (enterprise analytics), Otterly AI (SMB/solo practitioners), and Keyword.com’s AI Visibility tools.
Configure prompt sets and schedules: Automate recurring queries, segment by LLM, geo, and customer persona.
Benchmark competitors: Use dashboards to compare your brand’s citations, sentiment, and context against rivals.
Impact: In a Citation Labs audit, brands deploying automated tracking saw up to a 7x increase in LLM mentions post-intervention.
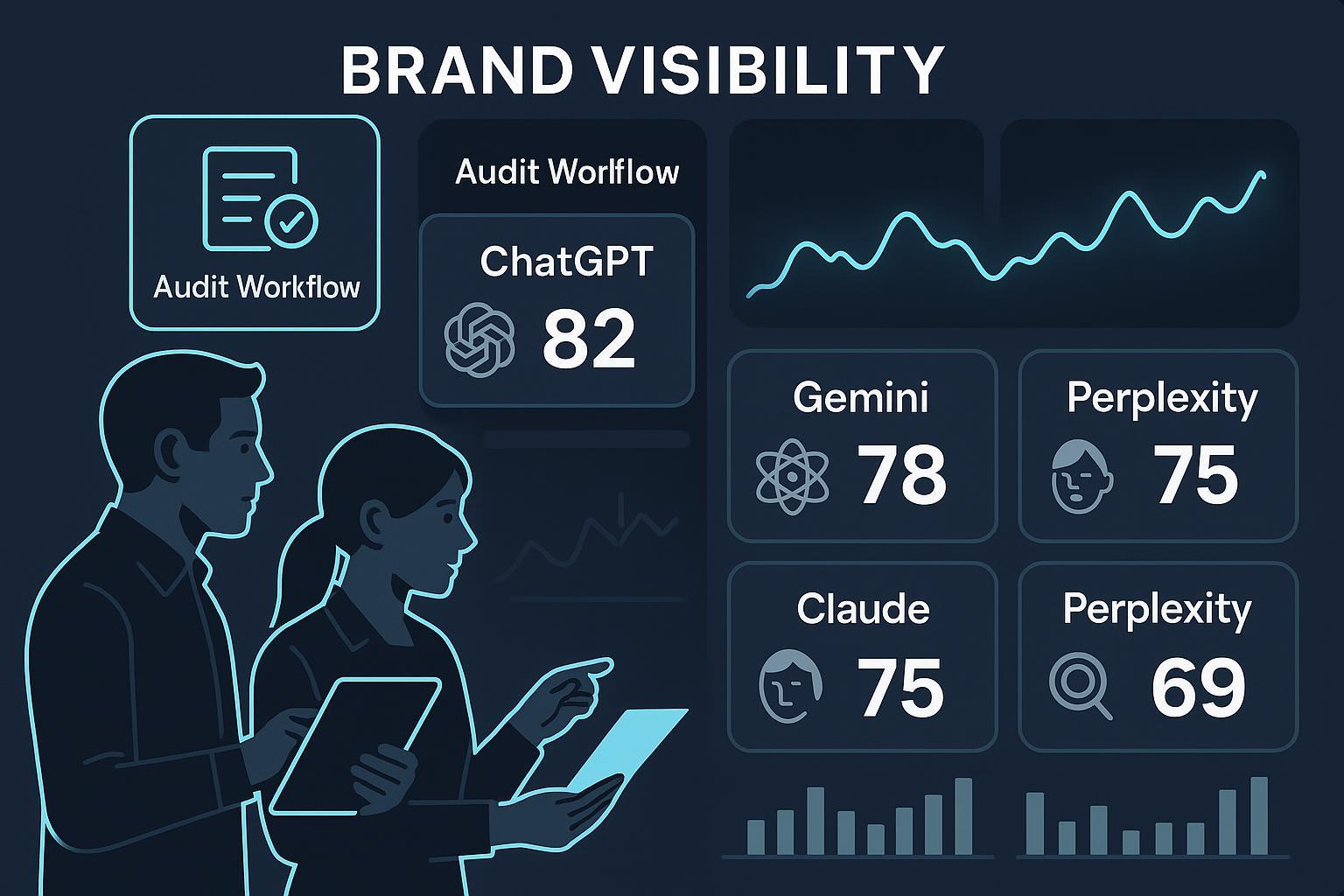
4. Score & Track: Develop Model-Agnostic LLM Visibility KPIs
What & Why: Systematic KPIs make LLM audits actionable and comparable over time. Pioneering frameworks such as the Retina Visibility Score™ and LLMO Resilience Score (LLMO White Paper) aggregate various factors: citation frequency, sentiment, authority, context quality, and competitive share-of-voice.
How:
Key metrics to track:
Citation frequency per LLM and prompt
Sentiment score of brand mentions
Context and accuracy quality
Authority of cited sources
Visibility share vs. competitors
Visualize in a scorecard: Use or adapt the LLMO multi-LLM scorecard template.
Set improvement targets: Benchmarks are evolving, but case studies show top brands achieving 3-7x baseline citation improvements post-audit (see below).
Impact: Translates audit data into board-ready reporting, enables clear before/after ROI demonstration, and supports iterative visibility improvement cycles.
5. Deep-Dive: Document Gaps, Surface Inconsistencies & Act
What & Why: The real value of an audit is not merely the score—it’s the actionable insights that surface data/structure gaps, outdated citations, bias, or inconsistencies between LLM responses.
How:
Highlight missing or erroneous brand references in LLM responses (knowledge panel gaps, old data, lack of citations).
Document citations: Trace visible references back to their sources (Wikipedia, third-party reviews, company sites, news).
Audit for consistency: Compare your brand’s mention context and frequency across ChatGPT, Gemini, Claude, and others.
Create an intervention playbook: Prepare prioritized actions (e.g., structured data/Schema.org markup fixes, PR-driven authoritative content, Wikipedia/knowledge graph updates, domain authority improvements).
Impact: A University of Phoenix case by Citation Labs reported a 35% revenue uplift within weeks of closing key LLM data and citation gaps.
6. Continuously Monitor and Benchmark—Don’t Treat It as One-Off
What & Why: LLMs update regularly, shift data sources, and can be influenced by recent news or technical interventions. Ongoing monitoring is essential for maintaining and improving position.
How:
Automate reporting: Schedule recurring audit cycles (monthly/quarterly) using platforms like Peec AI or Otterly AI.
Track competitor changes: Document when/why rivals rise or fall in LLM visibility (new PR, product launches, content shifts).
Join knowledge standardization efforts: Participate in online panels, industry forums, and contribute data to help establish emerging benchmarks for LLM brand KPIs.
Impact: Industry experts emphasize that routine audits outpace reactive fixes, securing sustainable visibility and futureproofing your digital presence.
Real-World Walkthrough: A Synthetic LLM Brand Audit Case
Scenario: A SaaS firm launches a quarterly LLM visibility audit using a hybrid manual (prompt logging) and automated tracking (Peec AI) approach, focusing on the queries “top project management software 2025” and “best SaaS for remote teams.”
Findings:
ChatGPT and Gemini mentioned the brand 1/10 times; Claude, 0/10; Perplexity, 2/10.
Sentiment varied: ChatGPT was neutral; Gemini contextualized the brand by user reviews; Claude ignored the brand.
Key citations originated from outdated blog posts; Wikipedia omitted the company entirely.
Actions Executed:
Updated Wikipedia and Schema.org entity data.
Launched authoritative PR campaigns and got featured in relevant directories.
Created third-party reviews to shape upstream data sources.
Result: Within 6 weeks, LLM mentions increased to 6/10 (ChatGPT, Gemini), 3/10 (Claude), and sentiment improved from neutral to positive; citation sources became more authoritative and current.
Downloadable Resources & Checklist
Conclusion & Next Steps: Take Control of LLM Visibility—Now
As LLMs cement their place as gatekeepers of digital reputation, only proactive, rigorous audit strategies can ensure your brand is discoverable and trustworthy in generative AI outputs.
Follow the proprietary workflow above:
Map and prioritize LLMs
Build robust, testable prompt sets
Deploy automated audit tracking tools
Score and benchmark your progress
Document and act on data gaps
Monitor relentlessly
The result: Greater digital authority, measurable traffic and revenue lift, and lasting competitive edge as the LLM landscape evolves.
Practice outpaces theory—implement the checklist, benchmark your next audit, and join the vanguard of future-facing brand managers.
Further Reading: