The Role of Data in AI Content Scoring


Data stands as the backbone of AI content scoring accuracy and reliability. Researchers measure dataset quality using statistical tools like KL divergence and Zipf’s law, requiring long, high-quality samples for stable results. F1 scores for detection models vary widely, from 0.33 to 0.96, showing that large, curated datasets drive better outcomes. The Data Role in content evaluation shapes strategy and ensures reliable results. Readers should consider their own data practices for AI-driven evaluation.
Key Takeaways
High-quality, large, and diverse datasets improve AI content scoring accuracy and reduce errors.
Consistent, timely, and relevant data helps AI models produce reliable and fair results.
Combining structured and unstructured data gives AI a fuller understanding of content quality.
Regular data audits and bias checks keep AI scoring fair and trustworthy.
Using feedback loops and analytics supports continuous improvement in AI content evaluation.
Data Role in Content Scoring
Foundation for AI Accuracy
The Data Role in content scoring begins with accuracy. AI models depend on large and diverse datasets to learn how to evaluate content. When researchers use more comprehensive data, they see a clear increase in accuracy. The METRIC-framework review shows that both dataset size and variety matter. Larger datasets reduce noise and improve the quality of labels. This leads to better AI performance.
A closer look at recent studies highlights this trend. The table below shows how accuracy improves as dataset size and diversity increase:
Study / Dataset Description | Accuracy / AUROC | Tools Evaluated | Dataset Size / Type |
|---|---|---|---|
ChatGPT-generated & AI-rephrased articles | 100% accuracy | ZeroGPT, GPT-2 Output Detector | Academic papers (150 texts) |
Oncology scientific abstracts (2021-2023) | 96% - 99.7% accuracy, AUROC up to 1.00 | Originality.ai, GPTZero, Sapling | 15,553 abstracts |
Human vs AI detection in student essays | 91% accuracy (Human vs AI), 82% (Human vs disguised AI) | GPTZero, ZeroGPT, Winston | 459 essays |
AI-generated text detection tools (AH&AITD dataset) | 97% accuracy, 98% precision, 96% recall, 97% F1-score | Originality.ai, Zylalab, GPTKIT, GPTZero, Sapling, Writer | 11,580 samples |
AI-based plagiarism detection tools | 98-100% accuracy | Originality.ai, Turnitin AI, Sapling, Winston AI, GPTZero, Copyleaks, ZeroGPT | Various datasets |
Aggregated AI detector outcomes in STEM writing | 98% precision, 2% false positives/negatives | Originality.ai, Copyleaks, GPTZero, DetectGPT | STEM student writing |
Researchers also visualize this relationship. The chart below shows that as dataset size grows, AI detection accuracy rises:
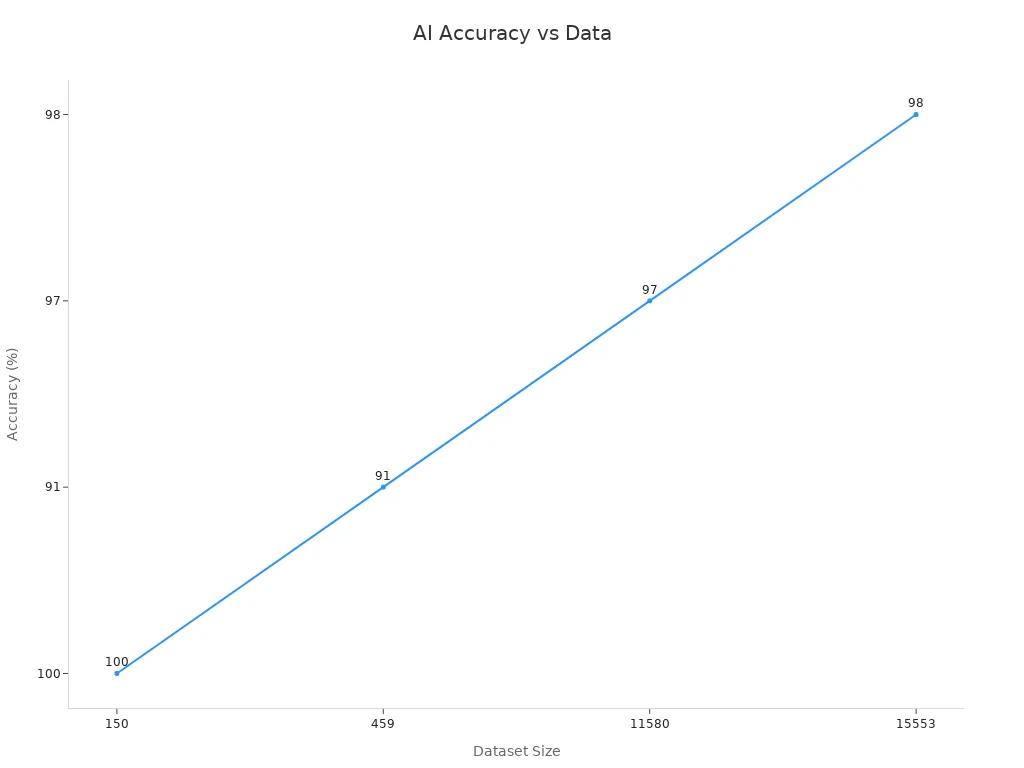
The Data Role in AI content scoring ensures that models learn from a wide range of examples. This approach helps the AI recognize patterns and make better decisions. When teams use high-quality, varied data, they see fewer errors and more reliable scores.
Note: The METRIC-framework review confirms that comprehensive data sources not only boost accuracy but also improve annotation quality. This leads to more trustworthy AI scoring.
Impact on Reliability
The Data Role extends beyond accuracy. Reliability means that AI content scoring produces consistent and trustworthy results. Studies show that using diverse datasets makes AI models more reliable. The WebTrust paper offers strong evidence for this claim:
Researchers trained WebTrust on over 140,000 articles from 21 domains, including fake news and scientific literature.
The dataset included samples with different reliability levels, created using data poisoning techniques.
They tested the model on more than 1,100 statements, each labeled by both AI and humans.
WebTrust outperformed three other language models and rule-based methods in all reliability metrics, such as Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and R-squared (R2).
The model produced a wider range of reliability scores, showing more nuanced predictions than other models.
A user survey with 53 participants confirmed that WebTrust improved the usability of reliability assessments.
The Data Role in reliability means that AI models can handle a variety of content types and sources. This reduces the risk of bias and ensures that scores remain stable across different scenarios. Teams that invest in diverse and well-labeled data see fewer false positives and negatives. They also gain more confidence in the results.
Data Types

Structured and Unstructured
AI content scoring systems rely on both structured and unstructured data. Structured data includes organized information such as ratings, scores, or labeled categories. This type of data is easy for machines to read and interpret. Unstructured data, on the other hand, consists of free-form text, images, or audio files. These data types require advanced processing to extract meaning.
A systematic review from Frontiers highlights the influence of these data types on AI performance. The review compares machine learning models that predict suicidal behaviors using structured and unstructured data. Structured data, such as psychometric scores or self-reports, provides targeted and easily interpretable information. Unstructured data, like clinical notes or electronic health records, offers a broader but less focused view. The study uses the area under the receiver operating characteristics curve (AUC) to measure model accuracy. Results show that structured data often leads to higher AUC values, indicating more accurate predictions. However, unstructured data can reveal hidden patterns and context that structured data may miss.
Tip: Teams should balance both data types to maximize AI scoring accuracy and capture a complete picture of content quality.
Key Data Points
Certain data points play a critical role in improving AI content scoring. Frequent auditing of vector databases and prompt data helps maintain high data quality. Real-time monitoring of data requests detects irrelevant or suspicious content. Analysis of prompt and retrieval segments identifies problematic data subsets. Hallucination and relevancy checks reveal where AI outputs diverge from factual content.
Key metrics that correlate with accurate AI content scoring include:
Error rate: Tracks incorrect or invalid model outputs.
Precision: Measures correct positive predictions.
Recall: Identifies relevant content accurately.
F1 score: Balances precision and recall.
Quality index: Aggregates multiple metrics for overall effectiveness.
These practices and metrics help teams reduce false positives, improve reliability, and ensure that AI content scoring remains trustworthy and effective.
Data Quality
Accuracy and Relevance
High-quality data forms the core of effective AI content scoring. Data must be accurate and relevant to ensure that AI models make correct decisions. When teams use precise and meaningful data, AI systems can identify patterns and deliver reliable scores. In the world of AI scoring, even small improvements in data quality can lead to significant gains.
A recent analysis highlights the impact of accuracy and relevance on AI outcomes. The table below shows how better data quality boosts performance in real-world applications:
Metric Description | Numerical Evidence |
|---|---|
Increase in lending accuracy over traditional methods | 85% boost |
Income frequency determination accuracy (salary) | 95% accuracy |
Income frequency determination accuracy (government) | 97% accuracy |
GINI score improvement using transaction data alone | 8% to 18% increase |
Number of credit variables used in AI models | Over 10 times traditional models |
Increase in loan approval rates with AI models | 20% to 30% increase while maintaining risk levels |
These numbers show that accurate and relevant data not only improves AI scoring but also drives better business outcomes. For example, lending platforms that use high-quality data see an 85% increase in accuracy compared to traditional methods. AI models that rely on precise income data reach up to 97% accuracy. More variables and better data lead to higher approval rates without raising risk.
When data is accurate and relevant, AI models reduce errors and avoid bias. This leads to fairer and more trustworthy content scoring.
Six principles define AI-ready data: diversity, timeliness, accuracy, security, discoverability, and machine-consumability. Diverse data exposes AI to many scenarios. Timely data keeps models up to date. Accurate data ensures correct outputs. Secure data protects privacy. Discoverable data allows easy access. Machine-consumable data enables smooth processing. Teams that follow these principles create strong foundations for AI scoring.
Consistency and Timeliness
Consistency and timeliness play a vital role in data quality for AI content scoring. Consistent data means that information stays the same across different systems and over time. Timely data means that information is current and available when needed. Both factors help AI models deliver stable and reliable results.
Experts use several metrics to measure consistency and timeliness. Consistency checks include comparing data across systems, standardizing formats, removing duplicates, and checking for logical agreement. Teams often follow a step-by-step process:
Identify all systems holding the data.
Select common data points.
Set a baseline system.
Extract data from each system.
Compare data points for differences.
Document any discrepancies.
Analyze the causes.
Resolve inconsistencies.
Make necessary changes.
Monitor for ongoing consistency.
Timeliness focuses on how fresh and available the data is. Teams check how often data updates, how quickly it becomes available, and whether it is accessible during important workflows. They also monitor for data outages and track the freshness of information.
Consistent and timely data ensures that AI scoring systems remain reliable and trustworthy. When data is up to date and uniform, AI models avoid outdated or conflicting information.
High data quality directly affects AI scoring outcomes. Accurate, relevant, consistent, and timely data helps AI models reduce bias and make fair decisions. Teams that invest in data quality see fewer errors, better performance, and more confidence in their AI-driven content scoring.
Data Processes
Collection Methods
Teams use several methods to collect data for AI content scoring. They often gather information from internal databases, public datasets, and third-party sources. Some organizations use human coders to label data, while others rely on generative AI models like Bard or ChatGPT for thematic coding. Studies show that human and AI coders can achieve high agreement levels, known as intercoder reliability. AI models often complete coding tasks faster than humans, which increases efficiency. However, human coders provide valuable context and judgment, especially when evaluating complex content. Many teams combine both approaches to balance speed and accuracy.
A sociotechnical approach also plays a role in data collection. This method considers social, organizational, and technical factors together. Teams use structured processes, such as developing codebooks and following step-by-step thematic analysis, to ensure reliable data collection. By integrating different perspectives, organizations improve the quality and relevance of their datasets.
Preparation Steps
After collecting data, teams must prepare it for AI models. Preparation includes cleaning the data, removing duplicates, and correcting errors. Teams standardize formats and label data clearly. Regular manual and automated reviews help detect and fix anomalies. Human-in-the-loop validation allows experts to interpret automated reports and adjust models as needed. These steps ensure that the data is accurate, diverse, and ready for machine learning.
Organizations also document data lineage to track where data comes from and how it changes. This transparency helps teams understand the data’s journey and maintain high standards.
Governance and Compliance
Strong governance and compliance protect data privacy and integrity. Organizations classify data by sensitivity and limit collection to what is necessary. They use role-based access controls, encryption, and anonymization to secure sensitive information. Regular audits and privacy impact assessments help identify and reduce risks.
Teams must follow regulations like GDPR, HIPAA, and the EU AI Act. These frameworks require transparency, risk assessments, and human oversight for high-risk AI systems.
Companies also train employees on ethical AI use and data handling. They develop incident response plans and engage third-party audits to ensure compliance. By following these practices, organizations build trust and maintain the integrity of AI content scoring.
AI Scoring Process

Scoring Criteria
AI content scoring systems use clear and measurable criteria to evaluate quality. These systems often start by defining goals, such as accuracy, safety, or style. Teams select criteria that match their use case. For example, essay grading tools may focus on grammar, organization, and argument strength. Support bots may prioritize accuracy and safety.
Scoring criteria usually include:
Technical skills: grammar, punctuation, and sentence structure.
Organization: logical flow and use of transitions.
Content analysis: evidence usage and strength of arguments.
Higher-order thinking: creative reasoning and original analysis.
Teams combine multiple metric categories to address real-world needs. They set baselines to measure initial performance and track trends over time. Thresholds help define acceptable performance and trigger alerts when scores fall below standards.
Ignoring expression and readability metrics can harm brand voice and user trust. Teams should always include these in their scoring criteria.
Custom metrics, such as LLM-as-a-Judge or code-based scoring, allow teams to tailor evaluation to specific needs. Human judgment remains important. It captures nuance and context that automated metrics may miss.
Metrics and Benchmarks
Reliable AI scoring depends on strong metrics and benchmarks. These tools help teams measure how well AI matches human judgment and meets quality standards.
Criterion/Benchmark | Description | Measurable Values/Accuracy |
|---|---|---|
AI vs Human Score Agreement | AI scores within one point of human scores | |
Writing Elements Evaluated | Technical, organization, content, higher-order thinking | High to medium-low accuracy |
Validation Methods | Cross-validation, blind grading, fairness analysis | Confirms alignment and equity |
Training Data Benchmark | Human-graded essays as ground truth | Over 10,000 essays, 100,000 graded solutions |
Continuous Improvement | Updates from educator feedback and research | Maintains academic standards |
Widely adopted benchmarks include GLUE, SuperGLUE, and MMLU, which test natural language understanding and multitask knowledge. BIG-bench and HELM evaluate broad AI capabilities, including fairness and robustness. Safety and alignment benchmarks, such as ToxiGen and RED-EVAL, check for harmful outputs and regulatory compliance.
Key metrics for AI scoring include:
Fairness scores
Precision, recall, and F1-score
Expression and readability (BLEU, ROUGE)
System reliability and downtime
Stakeholder feedback
Combining automated metrics with human review ensures AI scoring remains accurate, fair, and aligned with real-world needs.
Challenges and Solutions
Bias and Outdated Data
AI content scoring faces major challenges from bias and outdated information. Bias can enter at many stages, from data collection to algorithm design. Several real-world cases show how bias affects AI:
The COMPAS tool used court data that reflected racial prejudices, causing unfair predictions.
Amazon's hiring algorithm penalized resumes with the word "woman," showing gender bias from historical data.
Datasets often lack diversity, like ImageNet's overrepresentation of pale skin, leading to representation bias.
Measurement and evaluation bias can occur when features or benchmarks are chosen poorly.
Sampling bias and algorithmic bias further distort results.
Removing bias proves difficult, as seen when Amazon scrapped its flawed hiring tool.
Machine learning models often rely on datasets that do not represent all groups equally. This leads to unfair outcomes, especially for minorities. A systematic review found that only 25% of studies detected bias using metrics like accuracy and predictive equity. However, 80% of studies that tried to fix bias saw better model performance. These findings show that bias and outdated data can harm fairness and accuracy in AI content scoring.
False Positives/Negatives
False positives and false negatives present another challenge. A false positive happens when the AI marks something as correct when it is not. A false negative means the AI misses something important. Both errors lower trust in AI scoring.
Study (Year) | False Positives | False Negatives | Total Cases |
|---|---|---|---|
Balta (2020) | 6,135 | 9 | 17,896 |
Lang (2021) | 4,438 | 7 | 9,581 |
Lauritzen (2022) | 41,909 | 105 | 114,421 |
Raya-Povedano (2021) | 4,450 | 13 | 15,987 |
Larsen (2022) | 11,638 | 212 | 122,969 |
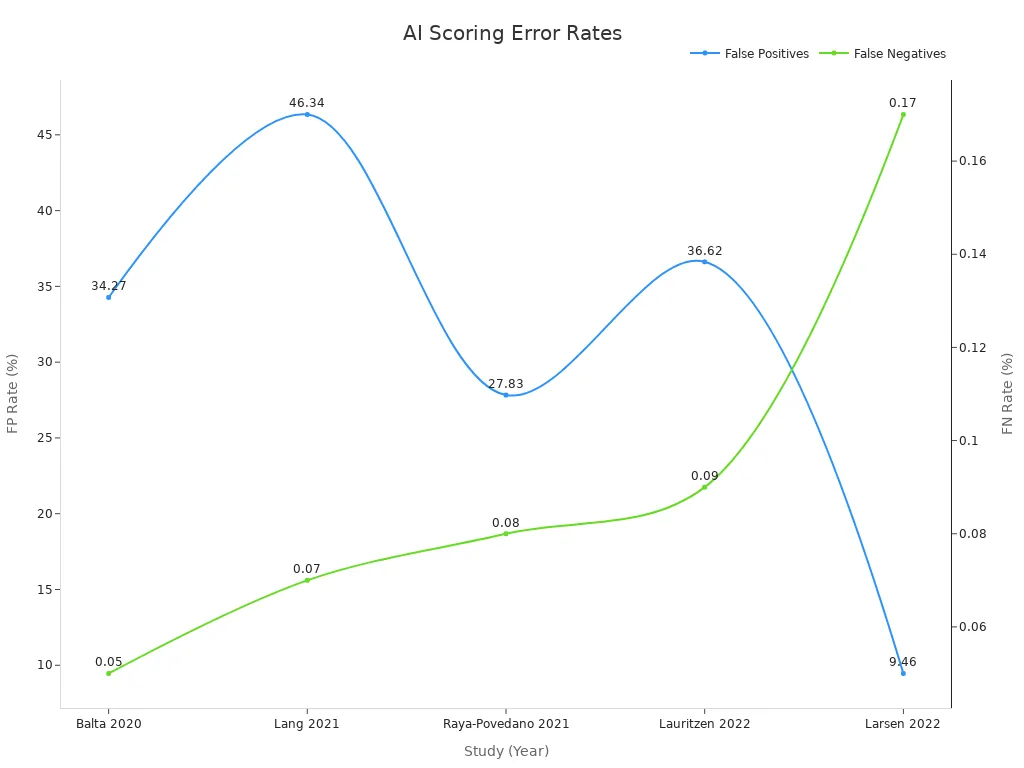
False positives can be more damaging than false negatives. They can cause anxiety and reduce trust in AI systems. Teams use diverse training data, hard negative mining, and careful threshold settings to reduce these errors. Regular evaluation with large and small test sets helps maintain balance.
Ensuring Data Quality
Teams must focus on data quality to overcome these challenges. They use several strategies:
Regularly update datasets to remove outdated information.
Audit data for bias and representation gaps.
Apply fairness metrics like F1-score, precision, and recall.
Use both automated and human reviews to catch errors.
Train models with diverse and balanced data.
High-quality data leads to fairer, more accurate AI content scoring. Teams that invest in data quality see fewer errors and more reliable results.
Data-Driven Improvement
Insights for Strategy
Organizations use data to shape content strategies and improve outcomes. They track user behavior, content performance, and engagement through analytics tools. The following steps show how teams use data-driven insights to guide decisions:
Track traffic sources, user actions, and conversions with Google Analytics.
Monitor keyword rankings and analyze competitors using SEMrush.
Identify top-performing social content and influencers with BuzzSumo.
Manage content and analyze cross-channel performance through HubSpot.
Study user interaction patterns with Hotjar’s heatmaps and session recordings.
Refine content topics and formats based on performance data.
Personalize content using audience demographics.
Focus distribution on high-performing channels.
Set clear goals and KPIs to measure effectiveness.
Continuously optimize content using real-time dashboards.
Teams also analyze audience demographics and behavior to tailor content. They identify popular topics, test different formats, and adjust schedules for peak engagement. These actions help organizations align their content with business goals and improve return on investment.
Predictive analytics and real-time monitoring support ongoing improvements in content quality and operational efficiency.
Feedback Loops
Feedback loops play a key role in content evaluation systems. They allow teams to collect, analyze, and act on feedback to improve quality. Companies like Amazon and Google use feedback from customers and employees to enhance products and services. Toyota’s Kaizen process uses worker feedback to boost efficiency and quality.
A typical feedback loop includes these steps:
Develop and carry out specific corrective actions.
Involve all stakeholders for support.
Document the process for accountability.
Set metrics to track effectiveness.
Reassess and gather feedback at regular intervals.
Use new data to evaluate success and make further changes.
This cycle ensures continuous improvement and measurable results.
Actionable Steps
Teams can take practical steps to strengthen the Data Role in content scoring:
Build a data-driven culture by training staff and encouraging data use in decisions.
Align data quality metrics with business goals to support efficiency and innovation.
Use automated tools and real-time dashboards for ongoing monitoring.
Establish clear data governance and integration frameworks.
Regularly review and update content strategies based on analytics.
Involve stakeholders in feedback processes to ensure broad support.
Set up regular meetings to review progress and adjust plans.
By following these steps, organizations can create a strong foundation for continuous improvement and maintain a competitive edge.
The Data Role in AI content scoring remains essential for accuracy and reliability. Teams should focus on managing data quality and following compliance standards. To improve content evaluation, they can:
Audit current data sources regularly
Train staff on data best practices
Adopting these steps helps organizations build stronger, data-driven marketing strategies.
FAQ
What is AI content scoring?
AI content scoring uses machine learning to evaluate the quality of digital content. The system checks for accuracy, relevance, and structure. Teams use these scores to improve writing and meet business goals.
Why does data quality matter in AI scoring?
High-quality data helps AI models make better decisions. Accurate and relevant data reduces errors and bias. Teams see more reliable results when they use clean, well-labeled data.
How do teams reduce bias in AI content scoring?
Teams use diverse datasets and regular audits. They check for fairness with metrics like precision and recall. Human review helps catch issues that automated systems might miss.
What are common challenges in AI content scoring?
Teams often face bias, outdated data, and false positives or negatives. Regular updates and audits help solve these problems. Using both human and machine reviews improves accuracy.
Can AI content scoring replace human judgment?
AI can support human reviewers but cannot fully replace them. Human judgment adds context and nuance. Teams get the best results by combining AI scoring with expert review.
See Also
Comparing Writesonic AI And QuickCreator For Content Creation
Complete Guide To Achieving SEO Success Using Perplexity AI
Strategies For Analyzing Content To Beat Your Competition
Top SEO Trends And Forecasts To Watch In 2024
How To Boost Engagement Using TikTok Analytics Tools Effectively
