Cómo construir un motor de SEO con IA escalable
¿Tu equipo invierte horas en investigación, briefs y auditorías, pero la velocidad de publicación y la calidad fluctúan? Diseñar un motor de SEO con IA escalable te permite convertir procesos frágiles en pipelines repetibles, medibles y más rápidos. En esta guía, vamos al grano: arquitectura, decisiones de stack, métricas y un workflow que podrás replicar.
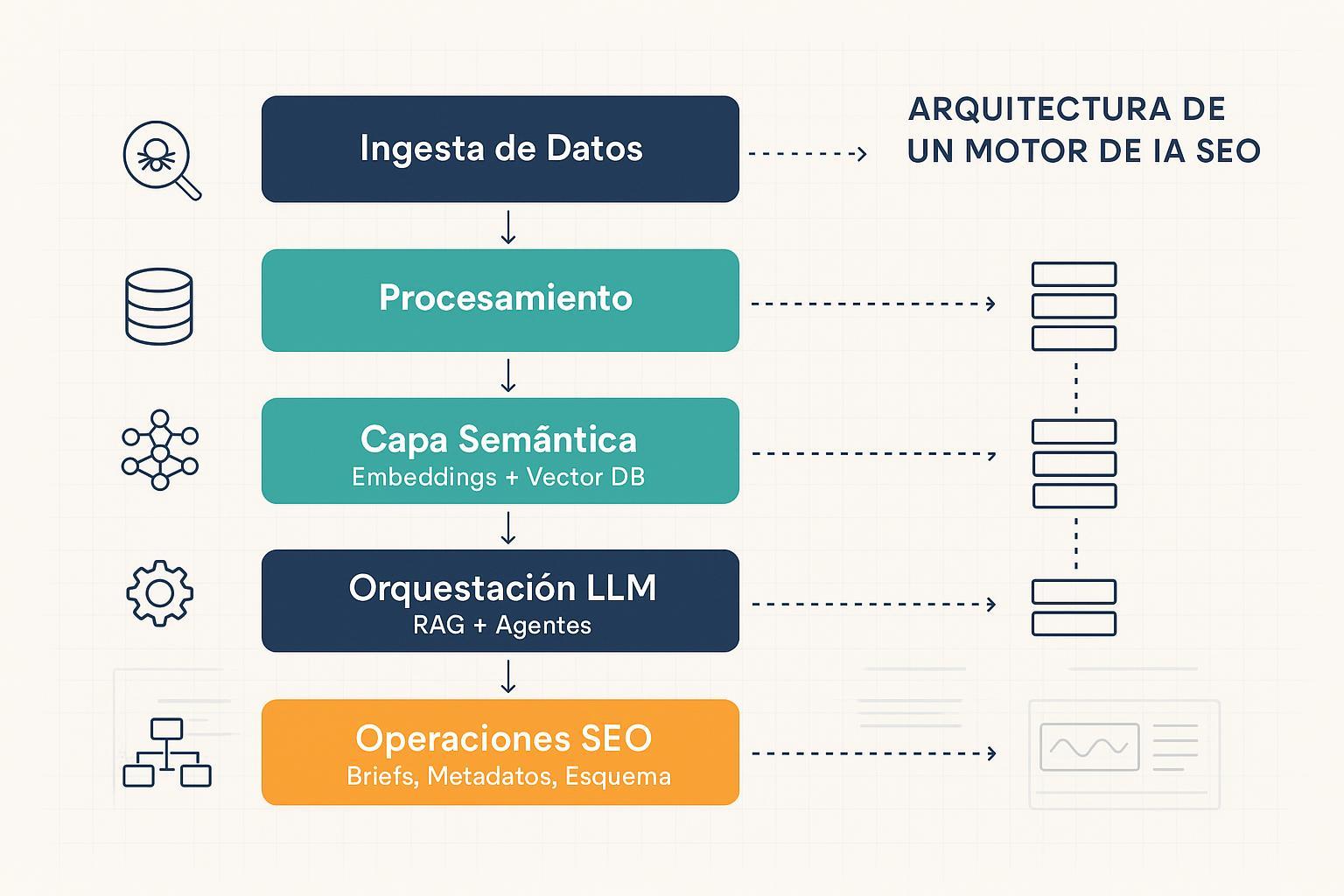
1) Arquitectura de referencia end‑to‑end
Piensa así: tu motor es un sistema por capas, desacoplado y orquestado por colas/servicios. La ingesta reúne fuentes como GSC/GA4, APIs de SERP, logs de servidor y bots, crawlers, CMS, inventarios, sitemaps y robots. El procesamiento aplica normalización y deduplicación con ETL/ELT en batch y streaming, más validaciones de calidad. La capa semántica genera y cachea embeddings, indexa en una base vectorial y habilita búsqueda híbrida (lexical + semántica). La capa de modelos/agentes ejecuta RAG, clasificación, clustering, etiquetado de intención y generación controlada con plantillas. Publicación/ops SEO cubre briefs, metadatos, schema, interlinking, auditorías y alertas. Observabilidad consolida paneles (GSC/GA4/CrUX) con costes, latencia y cobertura.
Tres decisiones te evitarán cuellos de botella: dividir tareas largas con colas y límites por proyecto para contener coste/latencia; cachear embeddings y resultados de SERP y colocalizar servicios que se llaman entre sí para reducir hops; y aplicar backpressure con políticas de reintento y circuit breakers para picos de carga. Para fundamentos de arquitectura de agentes y sistemas modulares, revisa la guía de Latenode en español “arquitectura completa de sistemas inteligentes”.
2) Ingesta y gobierno de datos
La calidad del motor depende de la calidad de tus datos y de su gobernanza. Conecta las APIs de Search Console y GA4 para extraer rendimiento (impresiones, clics, CTR, posición), cobertura e insights de comportamiento; si necesitas analítica avanzada, exporta GA4 a BigQuery. Revisa la documentación de Google Search Central y Analytics Data API. Complementa con SERP APIs (Google Custom Search, Bing; proveedores como SerpAPI o DataForSEO) para monitoreo competitivo y variaciones de resultados. Tus logs y crawls ayudan a modelar el crawl budget, detectar 4xx/5xx y cadenas de redirecciones, y a comprender prioridades de Googlebot. Mantén sitemaps XML limpios y robots.txt preciso, validando con las herramientas de Search Central.
En gobernanza, define esquemas por fuente, establece rutinas de deduplicación y checks de consistencia, respeta cuotas de API y agrega consultas en batch con caché para evitar latencias acumuladas.
3) Representación semántica y búsqueda híbrida
La semántica sostendrá investigación, clustering y generación controlada. Elige embeddings por precisión, latencia y coste: modelos gestionados como OpenAI o Cohere funcionan bien para empezar; si tu dominio lo permite, considera opciones autoalojadas de Sentence‑Transformers o Gemini embeddings para controlar privacidad y coste. En la base vectorial, HNSW suele ofrecer excelente relación latencia/recall, IVF facilita compresión y búsqueda en colecciones masivas, y PQ reduce memoria a cambio de una degradación moderada que debes validar en tu caso. La búsqueda híbrida —combinar BM25/lexical con vectorial y filtros estructurados— es especialmente efectiva en SEO. Evita términos obsoletos como “LSI”; céntrate en co‑ocurrencias modernas y embeddings.
Para proyectos con JavaScript, Google recomienda que el HTML inicial contenga contenido y datos estructurados y evitar el dynamic rendering salvo casos específicos. Consulta Google Search Central (SEO para JavaScript).
4) RAG y orquestación de LLMs
Separa recuperación y generación. Exige grounding: que los outputs citen y se basen en las fuentes recuperadas. Usa plantillas de prompts con instrucciones claras (tono, límites de extensión, citación, estructura) y herramientas/funciones cuando requieras acciones. Controla coste y latencia con límites por solicitud y proyecto, fallbacks automáticos entre modelos y paralelización de subtareas. Añade QA factual con re‑rankers/chequeos automáticos y revisión humana para contenidos críticos. Mantén observabilidad con tracing, memoria de contexto multi‑turno y detección de deriva.
5) SEO técnico y arquitectura web
Estructura y rendimiento determinan indexabilidad y experiencia. Organiza silos temáticos y pilares para mejorar navegación e interlinking (referencia: arquitectura en silo y pilares). Consolida duplicados con canonicals correctos y evita thin content. Mantén sitemaps dinámicos con lastmod y prioridad según frescura e impacto. En renderizado, aplica SSR/SSG/ISR según tipo de ruta y verifica que el HTML inicial incluya contenido y schema.
Core Web Vitals (umbral recomendado en el percentil 75)
Según las guías oficiales de Web Vitals en web.dev (2025) y PageSpeed Insights:
| Métrica | Umbral recomendado | Mejora práctica |
|---|---|---|
| LCP | ≤ 2.5 s | Mejorar TTFB, precargar recursos críticos, optimizar imágenes y fuentes |
| INP | ≤ 200 ms | Reducir trabajo JS, dividir tareas largas, hydration progresiva/selectiva |
| CLS | ≤ 0.1 | Reservar espacio con dimensiones explícitas, evitar inserciones inesperadas |
Para detalles y medición con DevTools/CrUX, revisa el blog de Chrome “Novedades en DevTools” (129).
6) Automatización SEO con IA: del discovery a los briefs y metadatos
Orquesta un pipeline que conecte investigación y producción: descubre y agrupa keywords con embeddings por intención/tema, valida con muestras y —cuando aplique— el silhouette score. Genera briefs con objetivos, estructura H2/H3, FAQs, enlaces internos y metadatos propuestos, siempre con revisión editorial obligatoria. Completa con títulos/descripciones y marcado schema.org (Article, Product, FAQ, BreadcrumbList, LocalBusiness) y valida en Rich Results Test. Mantén monitoreo activo: CWV (CrUX/GSC), indexabilidad (errores/canonicals/noindex), crawl budget (logs) y redirecciones/cadenas. Define gobernanza con límites de publicación automática, umbrales E‑E‑A‑T y control de estilo/terminología.
Si tu equipo necesita acelerar la fase de briefs y borradores, el constructor de outlines asistidos por SERP del AI Blog Builder para SEO puede apoyar a Content Ops sin interferir con la arquitectura técnica.
7) Evaluación y experimentación
Medir es la única forma de saber si escalas con calidad. Combina métricas offline (precisión de extracción/etiquetado, consistencia de resúmenes, relevancia de recuperación como nDCG/Recall@k y métricas de clustering como silhouette/DBI) con métricas online (CTR orgánico, posición media, clics/impresiones en GSC, CWV vía CrUX/GSC, cobertura, tiempo estimado de indexación y cambios en features de SERP/SGE). Estructura pruebas A/B de titles/snippets e interlinking con poblaciones/control, periodos y KPIs definidos antes de ejecutar. Para contexto adicional, revisa la guía de HubSpot “Guía de SEO técnico” y el análisis de SE Ranking “IA aplicada al SEO”.
8) MLOps/LLMOps y seguridad
La operación continua mantiene el sistema sano. Versiona pipelines y datasets curados; usa feature stores si entrenas modelos propios. Evalúa y versiona prompts/modelos con posibilidad de rollback; establece límites de coste/latencia por equipo y proyecto. Monitoriza con tracing de llamadas, consumo y deriva. Protege datos con enmascaramiento/anonimización de PII, gestión de secretos, controles de acceso, retención mínima y auditoría. Apóyate en pautas de proveedores (Google, Azure) y prácticas como MLflow.
9) Ejemplo de workflow operable (con mención de producto)
Divulgación: QuickCreator es nuestro producto. En la fase de contenidos, QuickCreator puede ayudar a convertir clusters en briefs, generar borradores multilingües y publicar en WordPress con un editor simple y controles SEO integrados. Integrado en un motor mayor, el ciclo típico sería: cada día, ingesta de GSC/GA4 y SERP, refresco de embeddings/cache y alertas de CWV/cobertura; cada semana, clustering actualizado, briefs generados, QA humano, metadatos/schema validados y auditorías técnicas; tras la publicación, despliegue controlado con interlinking, verificación en Search Console y observación de KPIs; y en retroalimentación, paneles unificados, experimentos A/B y ajustes de prompts y límites de coste.
10) Próximos pasos y checklist final
- Define objetivos de latencia y coste por ruta (p. ej., TTFB <800 ms; INP <200 ms; LCP <2.5 s).
- Selecciona tu stack de embeddings y vector DB (HNSW/IVF/PQ) y prueba recall/latencia en tu dominio.
- Implementa búsqueda híbrida y RAG con grounding y citación de fuentes.
- Orquesta pipelines de keywords→clusters→briefs→metadatos→QA→publicación y añade observabilidad.
- Valida renderizado (SSR/SSG/ISR) y schema con herramientas oficiales; evita dynamic rendering.
- Configura paneles GSC/GA4/CrUX; define KPIs y ventanas de observación; ejecuta pruebas A/B.
- Establece gobernanza: límites de publicación, umbrales de calidad y revisión humana.
- Documenta seguridad y cumplimiento (PII, secretos, accesos, retención).
¿Listo para pasar de procesos manuales a un motor que escala con control? Empieza por mapear tus datos críticos y definir métricas de éxito; el resto del sistema se construirá sobre esas decisiones.