Schema markup secrets: How structured data helps AI understand and cite your content

If you lead SEO or content ops, you already know structured data is not a silver bullet—but it remains one of the most reliable ways to expose the meaning of your pages to machines. In 2025, the goal isn’t just rich results; it’s helping AI systems resolve entities, summarize accurately, and cite you when synthesizing. Based on practice, here’s the blueprint that consistently produces fewer schema errors, stronger entity signals, and better eligibility for rich features—while giving AI models clearer context.
Important boundary to set up front: Google encourages structured data because it provides “explicit clues,” but it does not guarantee AI Overviews inclusion. Google’s guidance in the updated 2025 documentation makes this clear; see the explanation in the Google Search Central structured data intro (2025). Treat schema as the semantic foundation that supports understanding and visibility, not a ranking hack.
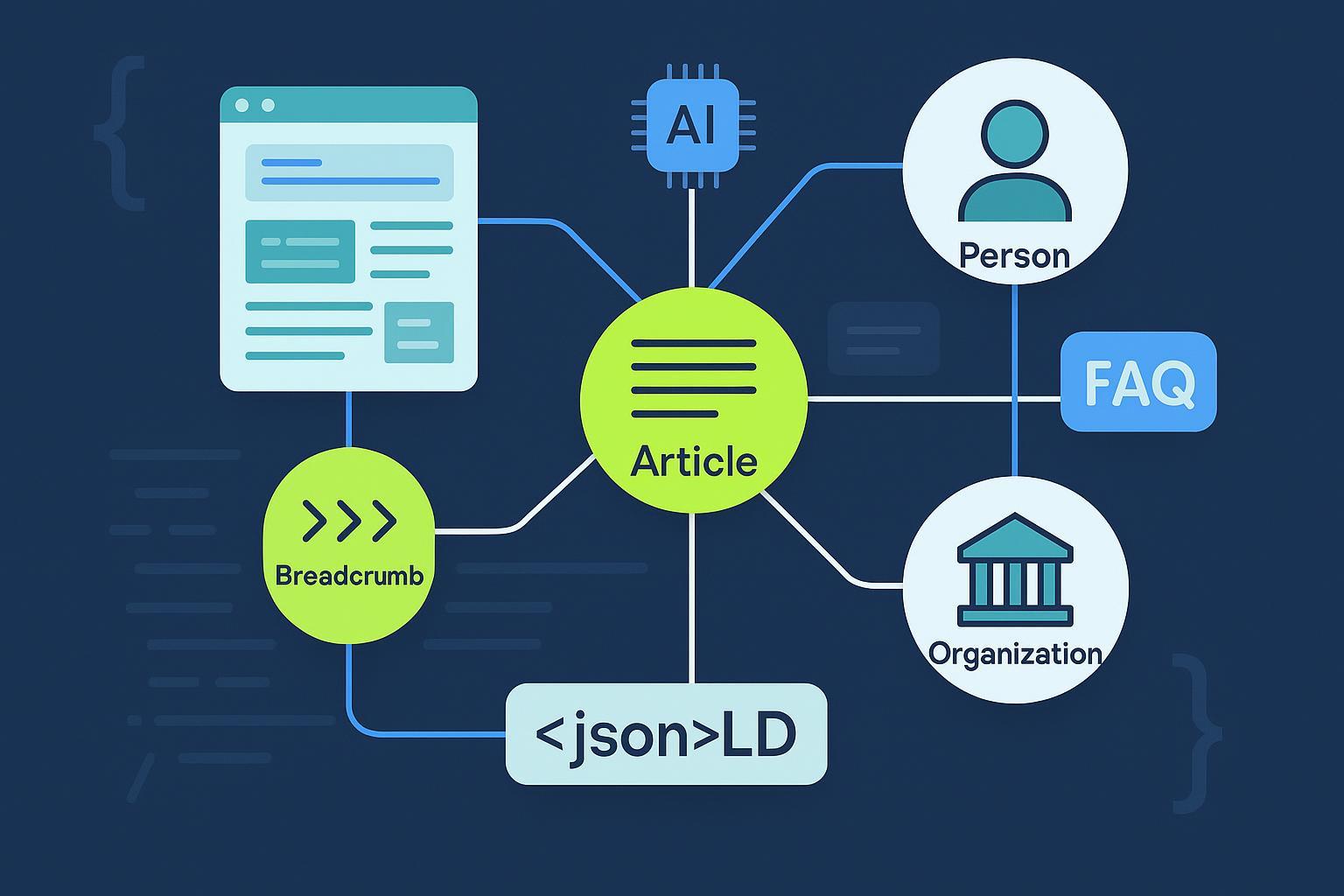
The minimal viable graph for content sites
For blogs, newsrooms, and SaaS content hubs, over-markup is common and counterproductive. In practice, a small, stable graph covers 80% of value:
- Article or BlogPosting (choose one consistently)
- Person (author)
- Organization (publisher)
- BreadcrumbList
Here’s a production-ready JSON-LD pattern that prioritizes correctness and entity stability.
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Organization",
"@id": "https://example.com/#org",
"name": "Example Inc.",
"url": "https://example.com/",
"logo": {
"@type": "ImageObject",
"url": "https://example.com/assets/logo.png"
},
"sameAs": [
"https://www.linkedin.com/company/example-inc/",
"https://twitter.com/example",
"https://www.wikidata.org/wiki/Q123456"
]
},
{
"@type": "Person",
"@id": "https://example.com/people/jane-doe#person",
"name": "Jane Doe",
"url": "https://example.com/people/jane-doe/",
"jobTitle": "Head of SEO",
"affiliation": { "@id": "https://example.com/#org" },
"sameAs": [
"https://www.wikidata.org/wiki/Q987654",
"https://en.wikipedia.org/wiki/Jane_Doe",
"https://www.linkedin.com/in/jane-doe/"
]
},
{
"@type": "BreadcrumbList",
"@id": "https://example.com/blog/schema-markup/#breadcrumbs",
"itemListElement": [
{
"@type": "ListItem",
"position": 1,
"name": "Blog",
"item": "https://example.com/blog/"
},
{
"@type": "ListItem",
"position": 2,
"name": "Schema Markup",
"item": "https://example.com/blog/schema-markup/"
}
]
},
{
"@type": "Article",
"@id": "https://example.com/blog/schema-markup/#article",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://example.com/blog/schema-markup/"
},
"headline": "Schema Markup Secrets",
"description": "How structured data helps AI understand and cite your content.",
"image": [
"https://example.com/assets/schema-cover-1200x630.jpg"
],
"datePublished": "2025-09-15",
"dateModified": "2025-10-01",
"inLanguage": "en",
"author": { "@id": "https://example.com/people/jane-doe#person" },
"publisher": { "@id": "https://example.com/#org" }
}
]
}
Why these properties matter:
- Stable
@idvalues let you reference the same Person and Organization across pages, reducing ambiguity. sameAslinks to authoritative identifiers help models resolve entities; Schema.org’s definition of sameAs describes it as the “URL of a reference page that unambiguously indicates the item’s identity”—see Schema.org sameAs.mainEntityOfPageandheadlinemap clearly to the page’s primary topic; avoid vague titles.inLanguageis optional but useful for analytics and QA in multilingual stacks; hreflang still does the heavy lifting for international targeting per Google’s localized versions documentation (updated versions referenced in 2025).
Entity linking and E-E-A-T you can verify
You don’t “turn on E-E-A-T” with a schema flag. Instead, align markup with visible credibility:
- Author page with bio, credentials, and editorial role; link it in Person.url and Article.author.
- Organization with a clean profile and real-world identifiers (official social, Wikidata/Crunchbase).
- Consistent publisher and author relationships in the graph.
Google’s Article structured data guidance highlights multi-author arrays and clear author information; see Google’s Article structured data page (2025). Pair this with your editorial standards—author bios, revision notes, and source citations—to make trust signals obvious to both humans and machines.
AI citation readiness: patterns that help systems synthesize
From practice, pages cited by AI features tend to share these traits:
- Clear definitions and Q&A sections that map cleanly to FAQ schema where appropriate.
- Stable entities (author, org) reused across your site via
@id. - Accurate, up-to-date facts and transparent citations inside the body copy.
Google explains that AI features synthesize information from multiple sources and cite them; see the AI features for site owners page (2024–2025) and the launch announcement in Google’s May 2024 AI Overviews blog. Schema doesn’t guarantee inclusion, but well-structured pages are easier for systems to parse.
If your content naturally includes Q&A, add FAQ markup only when the visible content matches the schema and the page is eligible in the Google Search Gallery (2025). Avoid stuffing FAQ or HowTo markup where it doesn’t belong; misalignment is a fast path to warnings or feature loss.
Validation and QA pipeline that catches real-world errors
A robust pipeline minimizes surprises:
- Local linting and unit tests for JSON/JSON-LD in your repo.
- Google Rich Results Test (RRT) for feature eligibility; test mobile-first and ensure dynamic JS injection is rendered. The RRT and structured data intro are covered in Google’s structured data documentation (updated 2025).
- Schema Markup Validator (SMV) for vocabulary correctness beyond Google’s features—use Schema Markup Validator.
- Search Console monitoring for live issues and coverage—see Google Search Console overview.
- Periodic audits using a tool comparison methodology like the 2025 overview in Sitebulb’s validation tools guide.
Error vs warning: Errors typically block eligibility; warnings are non-blocking but reduce enhancement quality. When in doubt, align visible content with the markup and remove non-essential properties that trigger warnings.
Scalable deployment workflows (WordPress, headless, enterprise)
On WordPress, use a schema framework that generates a sensible site-wide graph (e.g., Organization + Person + Article), then layer page-specific overrides in the editor. For headless stacks, generate JSON-LD server-side whenever possible, or ensure hydration timing allows the bot to render injected JSON-LD.
Example workflow using a modern AI blogging platform:
- Draft and edit content in an AI-assisted editor with schema checkpoints built into the publishing flow.
- Auto-generate Article/BlogPosting with Author and Publisher entities, then validate with RRT before publishing.
- Deploy and monitor structured data issues in Search Console.
First mention (example only): QuickCreator integrates AI writing, a block-based editor, and automatic schema checks tied to SERP analysis, which helps teams consistently ship valid Article/Person/Organization graphs across languages. Disclosure: This example uses QuickCreator, our own platform; it’s included to illustrate a repeatable workflow without promotional intent.
For broader collaboration patterns, see the hybrid editorial/SEO blueprint in AI content workflows for humans + AI (QuickCreator).
Troubleshooting playbook: fix the issues that actually break features
Typical failure modes and how to resolve them:
- Missing required properties: Start with the Search Gallery spec for the feature you’re targeting and map each “required” and “recommended” field to content inputs before coding.
- Mismatch between markup and visible content: If your page shows a single author, don’t declare multiple authors. Ensure dates, headlines, and images match.
- Invalid values and types: Validate arrays vs strings, dates in ISO format, and URL fields that return 200 OK.
- Outdated data: Product pricing, event dates, availability—set CMS-level reminders or automated checks to update schema in sync with content.
- Dynamic JS injection not rendering for bots: Confirm rendering in RRT, minimize client-only schema injection, and prefer server-side JSON-LD when feasible.
- Internationalization mistakes: Use bidirectional hreflang across locales and keep locale-specific URLs separate; guidance in Google’s localized versions docs applies.
inLanguagemay assist QA, but hreflang remains primary.
When you encounter a persistent issue, strip the graph down to the minimal entities, resolve errors, then re-add properties incrementally. This iterative approach prevents hidden conflicts from compounding.
Measurement: prove impact without magical thinking
Measure what structured data can influence directly and what it supports indirectly:
- Rich result eligibility and impressions (Search Console enhancement reports).
- CTR changes for pages that gain rich results vs controls.
- AI citation incidence: track when AI features include your page among cited sources.
For controlled tests, run A/B experiments on schema elements and observe changes in eligibility/CTR, using repositories like SearchPilot’s case studies archive (ongoing). For broader context on AIO behavior and expectations, see AI summaries and SEO in 2025 (QuickCreator) and correlate with your own Search Console data.
Advanced patterns: when to extend and when to hold back
Extend thoughtfully when your content genuinely qualifies:
- VideoObject for embedded first-party videos with transcripts and key moments.
- Product, Review, and AggregateRating for commerce experiences, following Google’s latest requirements.
- HowTo where steps are explicit and visible.
Track feature churn and deprecations via the Google Search documentation updates page (2025). Don’t chase deprecated features or speculative markup. If a feature disappears from the Search Gallery, reassess your implementation and reporting expectations.
For developers needing a quick reference to required properties and technical on-page factors, consult the SEO developer cheat sheet (QuickCreator) and align your templates accordingly.
Implementation checklist (copy/paste for your team)
- Define stable
@idURIs for Organization and each Author; reuse across pages. - Implement Article or BlogPosting with
mainEntityOfPage,headline,image,datePublished,dateModified,author,publisher. - Add BreadcrumbList that mirrors your visible breadcrumbs.
- Link Person and Organization to authoritative
sameAsprofiles. - Validate in Rich Results Test (mobile) and Schema Markup Validator; fix errors first, warnings second.
- Launch with Search Console monitoring; prioritize pages with high potential for rich results.
- For multilingual sites, complete hreflang pairs and localize schema properties (
headline,description). - Establish CI/CD gates: JSON linting, unit tests for required properties, and scheduled audits.
- Document an editorial standard for author bios, citations, and update cadence.
- Review Google’s Search Gallery and Updates monthly to keep pace with feature changes.
Troubleshooting checklist
- Does each targeted feature have all required properties?
- Do schema values exactly match the visible page content?
- Are
@idvalues unique, stable, and reused correctly? - Do
sameAslinks point to authoritative profiles and identifiers? - Does the page render JSON-LD on mobile UA in RRT?
- Are locale URLs correctly connected via hreflang?
- Are there outdated dates, prices, or availability fields?
Final notes and guardrails
- Schema is supportive, not determinative, for AI Overviews—anchor your expectations to what Google documents and your own data. The principle is reiterated in the 2024–2025 guidance across Google’s structured data intro and AI features overview.
- Favor clarity over complexity. A small, stable graph beats a sprawling, brittle one.
- Keep humans first: visible trust signals and accurate facts matter more than any specific property.
If you apply this blueprint—minimal viable graph, stable entities, disciplined validation, and measured iteration—you’ll reduce schema noise, improve eligibility for features that matter, and give AI systems the clean signals they need to understand and cite your content accurately.
