How to Run AI-Driven A/B/n Creative Testing for Search Ads in 2025

If you manage Google Ads or Microsoft Advertising in 2025, you can level up creative performance by combining platform-native features with AI-driven workflows. This guide shows you, step by step, how to design, launch, and evaluate A/B/n tests for Responsive Search Ads (RSAs), when to use fixed-split experiments vs. adaptive (bandit-like) allocation, and how to make confident decisions without heavy math.
Outcome: You’ll finish with a repeatable playbook to plan, run, and roll out winning creative—complete with guardrails, sample-size guidance, sequential stop rules, and troubleshooting.
Difficulty and time: Intermediate. Expect 60–90 minutes to set up your first test, then 2–4 weeks (typical) to reach a decision, depending on volume.
Before You Start: Readiness Checklist (15 minutes)
- Measurement
- Confirm your primary conversion is correctly configured (used for bidding) and secondary conversions are excluded from “Conversions” unless intended. See Google’s explanation of the difference in About primary vs. secondary conversion actions (Google Ads Help, 2024–2025).
- If you capture leads, enable enhanced conversions to improve match quality. For GTM deployments, follow Configure GTM for enhanced conversions (Google Ads Help, 2024–2025).
- If you close deals offline, plan to import conversions using GCLID/WBRAID/GBRAID as documented in Manage Offline Conversions (Google Ads API, 2024–2025).
- Volume
- Baseline guideline: aim for ≥300 clicks per week in the ad group(s) under test and target at least 50–100 total conversions across all variants over the test window for directional calls.
- Account hygiene
- Keep the landing page constant when testing copy. Avoid overlapping tests in the same ad group. Ensure budgets and bid strategies won’t throttle exploration.
- Policy
- Keep copy professional and compliant (avoid ALL CAPS, gimmicky punctuation, or unsubstantiated claims) per Editorial style and spelling (Google Ads policy, 2024–2025). Microsoft mirrors similar editorial standards and flags violations under Editorial failure reason codes (Microsoft Advertising, 2023–2025).
Verification checkpoint
- Fire a test conversion and confirm it appears in the “Conversions” column (primary goal) within expected delay.
- Confirm budgets, bid strategy, audiences, and landing pages are identical across planned variants.
Choose Your Experiment Design
You have three viable paths. Pick based on your goal, volume, and need for inferential rigor.
- Option A — Fixed-split Experiments (highest learning quality)
- Use a clean 50/50 (or 33/33/33) traffic split and change only the creative. This is best when you need defensible learnings and clear causality.
- Option B — RSA Asset Testing in Production (fastest iteration)
- Load multiple distinct assets into a single RSA and let the platform rotate and score. This is best for continuous improvement with less experimental control.
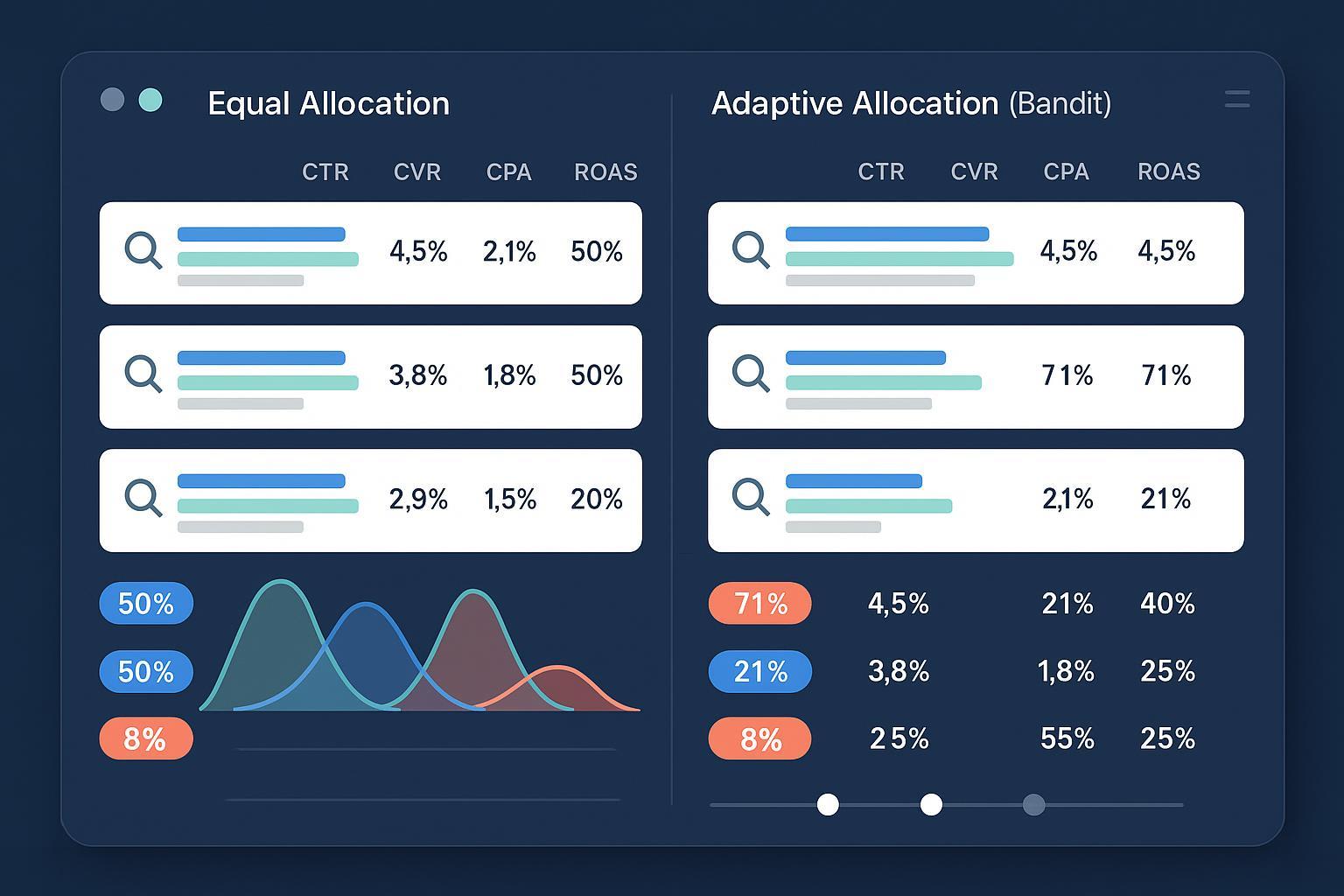
- Option C — Lightweight Bandit Workflow (dynamic allocation)
- Adjust serving over time toward better variants while reserving 10–20% for exploration. This shines when volume is uneven or when you want ongoing optimization without hard experiment boundaries.
Pro tip: If you’re starting from scratch or need clarity for stakeholders, begin with Option A. Once you have a winning baseline, maintain performance with Option B or a bandit-style cadence (Option C).
Google Ads: Fixed-Split Experiments (A/B/n) — Step-by-Step
Why this path: Cleanest causal readouts and the most stakeholder-friendly evidence.
- Create an experiment with even traffic
- In Google Ads, build a custom experiment from Experiments. Google’s walkthrough covers creating experiment groups, assigning campaigns, and setting the split in Create and manage experiments for Search (Google Ads Help, 2024–2025).
- For power, use an even split (e.g., 50/50). Google discusses power considerations and recommends even splits in Campaign guidance for experiments: 50/50 split for power (Google Ads Help, 2024–2025).
- Control your variables
- Duplicate the campaign (or arm) and change only ad creative. Keep budgets, bid strategy, audiences, negatives, and landing pages the same. Do not add new keywords mid-test.
- Build RSA variants correctly
- Respect RSA limits: up to 15 headlines (30 chars) and up to 4 descriptions (90 chars). See specs in About responsive search ads (Google Ads Help, 2024–2025).
- Pin sparingly unless legally required. Let the system explore combinations.
- Tag hypotheses and assets
- Label each RSA with your hypothesis (e.g., “Social proof vs. urgency”). This keeps reporting clean and repeatable.
- Launch and let it learn
- Expect automated bidding to re-enter learning after material changes; allow time to stabilize, per About bid strategy statuses and learning (Google Ads Help, 2024–2025).
- Monitor without “peeking” decisions
- Track primary outcomes (Conversions, CPA/tCPA, ROAS/tROAS). CTR and CVR are useful diagnostics but not decision KPIs if they conflict with your primary goal.
- Decision rules (practical thresholds)
- Duration: Run at least 1–2 full business cycles (often 2–4 weeks), longer if volume is low.
- Sample: Target ~25–50 conversions per variant before calling a winner (use the higher end for closer effects).
- Stability: Require the leading variant to maintain its advantage for 7 consecutive days before you declare it.
- Roll out the winner
- Apply the winning arm back to the original campaign using the experiment apply flow, as outlined in Create and manage experiments for Search (Google Ads Help, 2024–2025).
Verification checkpoints
- Mid-test: Each arm has similar impressions and budget delivery; no mid-test changes to bids/budget/targeting occurred.
- End-test: Winner meets conversion threshold and stability window; landing page remained constant.
Google Ads: RSA Asset Testing in Production — Step-by-Step
Why this path: Speed and simplicity. Accepts less control in exchange for faster, ongoing optimization.
- Assemble diverse, policy-safe assets
- Build 8–12 distinctive headlines and 3–4 descriptions across angles (benefit, proof, objection handling, urgency). Stay within limits from About responsive search ads (Google Ads Help, 2024–2025).
- Pin only what’s essential
- If you must pin (e.g., legal disclaimers), pin to a minimal set of positions; otherwise let the system explore. Google also notes RSAs may sometimes display fewer headlines or reuse a headline as a description when predicted to help, covered in Drive more performance from AI-powered Search ads (Google Ads Help, Feb 2024).
- Use diagnostics, not vanity metrics
- Improve coverage and diversity as guided by Ad Strength, but don’t optimize to the score itself. Treat it as a diagnostic per Ad Strength guidance for RSAs (Google Ads Help, 2024–2025).
- Read asset insights and combinations
- Review asset ratings (Pending/Learning, Low, Good, Best) and impression share in Assets reporting per See asset performance details (Google Ads Help, 2024–2025). Use the RSA combinations view to spot high-performing assemblies, as described in Drive more performance from AI-powered Search ads (Google Ads Help, Feb 2024).
- Make pragmatic calls
- Pause assets that consistently drag CPA/ROAS while protecting coverage. Keep 1–2 experimental angles live to avoid creative fatigue.
Microsoft Advertising: Experiments, Ad Variations, and RSAs — Step-by-Step
Why this path: Parallel to Google Ads with slightly different UI terms. Use Experiments for clean A/B, and Ad Variations for bulk copy edits.
- Experiments (fixed-split)
- From an existing Search campaign, create an experiment, set a 50/50 split, and change only creative. Keep bids, budgets, audiences, and landing pages equal. Run 2–4 weeks or until your conversion threshold is met.
- Ad Variations (bulk copy tests)
- Use Ad Variations to run systematic find/replace or append/prepend changes across many ads at once. Schedule, monitor, and apply winning edits account-wide.
- RSA specs and pinning
- Microsoft RSAs support 3–15 headlines (30 chars) and 2–4 descriptions (90 chars). Use pinning sparingly, as outlined in Responsive Search Ads guide (Microsoft Learn, 2024–2025).
- Editorial and compliance
- If ads are rejected, review specific editorial failure reasons and fix formatting/trademark issues using Editorial failure reason codes (Microsoft Advertising, 2023–2025).
Verification checkpoints
- Ensure identical delivery eligibility between control and trial (budget caps, targeting, device settings). Confirm the UET tag and conversion goals are firing before launch.
Generate Better Variants with AI (Policy-Safe and On-Brand)
Use AI to ideate and diversify angles, then filter through brand and policy checks.
Prompt structure you can copy
- Inputs: audience segment, primary value prop, key proof points, target queries/intent, disallowed claims, brand voice constraints, and must-have keywords.
- Output requirements: 12 headlines (≤30 chars), 4 descriptions (≤90 chars), variety across benefits/objections/urgency/CTA, and 1–2 legally required lines flagged for pinning.
- Policy guardrails: professional capitalization, no excessive punctuation, no unverifiable claims (align to page). See Google’s guidance in Editorial style and spelling (Google Ads policy, 2024–2025).
Example mini-brief you can paste into your AI tool
- Audience: CFOs at mid-market SaaS companies
- Value prop: Reduce billing errors by 40% with automated reconciliation
- Proof: SOC 2 Type II, 1,200 customers, G2 4.8/5
- Target intents: “automated billing reconciliation,” “reduce AR errors,” “close books faster”
- Disallowed: guarantees of results, “free forever,” competitor names
- Voice: Clear, credible, professional; avoid hype
- Output: 12 headlines (≤30 chars), 4 descriptions (≤90 chars). Flag two legal lines for pinning.
Preflight checks
- Readability (7th–9th grade), keyword presence, brand/legal signoff, and alignment with the landing page.
Metrics, Sample Sizes, and Decision Rules (No Heavy Math)
Pick the one primary metric that matches your objective:
- Lead gen: Conversions or CPA/tCPA
- Ecommerce/trial: ROAS/tROAS or Conversions value
Use secondaries (CTR, CVR, Quality proxies) as diagnostics, not tie-breakers. If they disagree with the primary metric, investigate funnel or landing-page issues.
Practical thresholds
- Fixed-split A/B/n:
- Duration: Minimum 2 weeks; preferably 2–4 weeks to span seasonality/weekly cycles.
- Sample size: Aim for ~25–50 conversions per variant. The lower end is okay for large effects; use the upper end when variants are close.
- Stop rule: Require the leading variant to sustain its advantage for 7 consecutive days.
- RSA-in-production or bandit-like testing:
- Exploration budget: Keep 10–20% of traffic for exploration to avoid premature convergence.
- Safety rule: Pause a variant that is ≥2x worse on CPA (or materially worse on ROAS) after it accrues at least 10–15 conversions.
Power and learning caveats
- Even traffic splits increase statistical power; Google highlights this in Campaign guidance for experiments: 50/50 split for power (Google Ads Help, 2024–2025).
- After creative changes, automated bidding re-enters a learning state; allow time to stabilize per About bid strategy statuses and learning (Google Ads Help, 2024–2025).
Lightweight Bandit Workflow (Adaptive Allocation) — How-To
When speed and cumulative performance matter, you can approximate a multi-armed bandit approach without heavy infrastructure.
- Start with 2–4 materially different variants
- Too many variants slows learning; retire near-duplicates.
- Pre-commit your guardrails
- Exploration: Reserve 10–20% of impressions for exploration at all times.
- Safety: If a variant hits ≥2x CPA vs. the best variant after ≥10–15 conversions, pause it.
- Stability: Require an improvement to persist for 7 consecutive days before shifting more traffic.
- Adjust allocation weekly
- If Variant B outperforms A on the primary metric and meets stability, increase B’s share (e.g., from 50% to 65%), while keeping your 10–20% exploration floor for other variants.
- Validate with simple bandit intuition
- Upper Confidence Bound and Thompson Sampling are popular choices. A practitioner-friendly explanation of UCB1 is in The UCB1 algorithm for multi-armed bandit problems (Microsoft Learn, 2019). Use the ideas to keep exploration alive and avoid overreacting to noise.
- Re-check combinations and assets (RSAs)
- In Google Ads, review RSA asset ratings and the combinations view to confirm the platform’s assembly aligns with what your policy and brand allow, per See asset performance details (Google Ads Help, 2024–2025) and Drive more performance from AI-powered Search ads (Google Ads Help, Feb 2024).
Rollout and Scaling
- Apply the winner
- In Google Ads Experiments, apply the winning arm back to the original campaign as documented in Create and manage experiments for Search (Google Ads Help, 2024–2025).
- Stabilization window
- After rollout, monitor for 7–10 days to ensure KPIs hold in production traffic.
- Creative library
- Document winning angles, headlines, and descriptions with labels. Reuse in sibling ad groups with similar intent and retest in new contexts.
- Cadence
- Introduce one new hypothesis every 2–4 weeks to avoid fatigue while keeping a stream of learnings.
Troubleshooting (If X, Then Y)
- Low volume (can’t reach thresholds)
- Collapse thin ad groups; broaden match types carefully; increase budgets from “Limited by budget”; extend test duration.
- Uneven delivery between variants
- Check for budget caps, device/location exclusions, audience mismatches, or overlapping experiments. Use even split (50/50) for fixed tests per Campaign guidance for experiments: 50/50 split for power (Google Ads Help, 2024–2025).
- Policy disapprovals
- Remove ALL CAPS, excessive punctuation, or restricted claims. Review Editorial style and spelling (Google Ads policy, 2024–2025) and Microsoft’s Editorial failure reason codes (Microsoft Advertising, 2023–2025).
- Learning phase noise after big changes
- Give bidding time to re-learn before judging results, per About bid strategy statuses and learning (Google Ads Help, 2024–2025).
- Confounded tests
- Don’t change keywords, bids, budgets, or landing pages mid-test. Pause the test and restart with a clean setup if critical changes are needed.
Templates and Checklists
Pre-commitment test plan (copy/paste)
- Campaign(s):
- Ad group(s):
- Test type: Fixed-split / RSA-in-production / Bandit
- Hypothesis and success metric: (e.g., “Urgency headline improves tCPA”)
- Variants and distinguishing angle(s):
- Traffic split: (e.g., 50/50 for fixed; exploration floor 15% for bandit)
- Duration minimum: (e.g., 3 weeks; cover 2 billing cycles)
- Sample targets: (e.g., ≥35 conversions per variant)
- Stop rules: (e.g., leader must hold for 7 consecutive days)
- Safety rules: (e.g., pause if ≥2x CPA after ≥12 conversions)
- Guardrails: No changes to bids/budgets/targeting/LP mid-test
- Stakeholders + signoff date:
AI prompt template for RSA variants
- Objective: Generate policy-safe RSA assets for [product/offering]
- Inputs I’ll provide: Audience, value prop, proof, target queries, disallowed claims, voice guide
- Requirements to follow strictly: 12 headlines (≤30 chars), 4 descriptions (≤90 chars), diversify angles (benefit, proof, objection, urgency, CTA), flag 1–2 legal lines for pinning
- Constraints: Professional capitalization, no hype, claims must match landing page
- Output format: Headline list and description list; note any flagged legal lines
QA checklist (pre-launch)
- Measurement: Primary conversion appears in “Conversions”; enhanced conversions configured if applicable via GTM enhanced conversions setup (Google Ads Help, 2024–2025)
- Eligibility: Same bids, budget, audiences, devices, and landing page across variants
- RSA assembly: Assets within limits per About responsive search ads (Google Ads Help, 2024–2025); pinning minimal
- Policy: Editorial style compliant per Google Ads policy (2024–2025); Microsoft editorial codes reviewed if applicable
Quick Reference Links
- Google Ads — Create and manage experiments (Search): Create and manage experiments for Search (2024–2025)
- Google Ads — Experiment power and traffic split: 50/50 split for power (2024–2025)
- Google Ads — RSA specs and pinning: About responsive search ads (2024–2025)
- Google Ads — Ad Strength guidance: Ad Strength is a diagnostic (2024–2025)
- Google Ads — Asset performance and combinations: Asset performance details (2024–2025) and RSA combinations and one-headline flexibility (Feb 2024)
- Google Ads — Bid strategy learning: Bid strategy statuses (2024–2025)
- Google Ads — Conversions setup: Primary vs. secondary conversions (2024–2025); GTM enhanced conversions (2024–2025); Offline conversions API (2024–2025)
- Microsoft Advertising — RSAs: Responsive Search Ads guide (2024–2025)
- Microsoft Advertising — Editorial: Editorial failure reason codes (2023–2025)
- Bandits — Practitioner background: UCB1 algorithm explained (Microsoft Learn, 2019)
You now have a 2025-ready, AI-powered A/B/n testing workflow for search ads. Start with a clean fixed-split test to establish a baseline winner, and then shift into RSA-in-production or bandit-style iteration to keep performance improving with controlled risk.
