Composable CDP, Explained: Architecture, Trade‑offs, and When to Choose It

If you’ve heard “composable CDP” and wondered whether it’s just reverse ETL with a new label, you’re not alone. In 2025, composable CDP refers to an architecture—not a product SKU—that assembles customer data platform capabilities around your own warehouse or lakehouse. Instead of sending all customer data into a vendor’s black box, you compose data collection, identity, modeling, activation, and governance as modular pieces that operate directly on your governed data.
According to the CDP Institute’s 2024 primer, the composable model contrasts with “packaged CDPs,” which bundle these capabilities and maintain their own data store; composable emphasizes flexibility and control while accepting more integration work. See the CDP Institute’s overview in the 2024 article, Composable CDPs vs Packaged CDPs: A Primer.
What a composable CDP is—and isn’t
- Is: A modular, warehouse/lakehouse‑native approach that uses interoperable components to deliver CDP outcomes (unified profiles, segmentation, activation, measurement) directly on your data.
- Isn’t: A single tool, “reverse ETL only,” or just “our warehouse.” CDP capabilities also include identity resolution, consent enforcement, governance, and purpose‑built models for customer use cases.
Why it’s gaining traction in 2025
- First‑party data strategy remains priority, while third‑party cookie timelines have shifted. Google’s 2025 update indicates it is not proceeding with a full, immediate phase‑out of third‑party cookies in Chrome, shifting to a user‑choice path under regulatory review; see the Privacy Sandbox 2025 update.
- Warehouses and lakehouses now provide streaming, governance, and sharing features that make customer activation feasible without duplicating data.
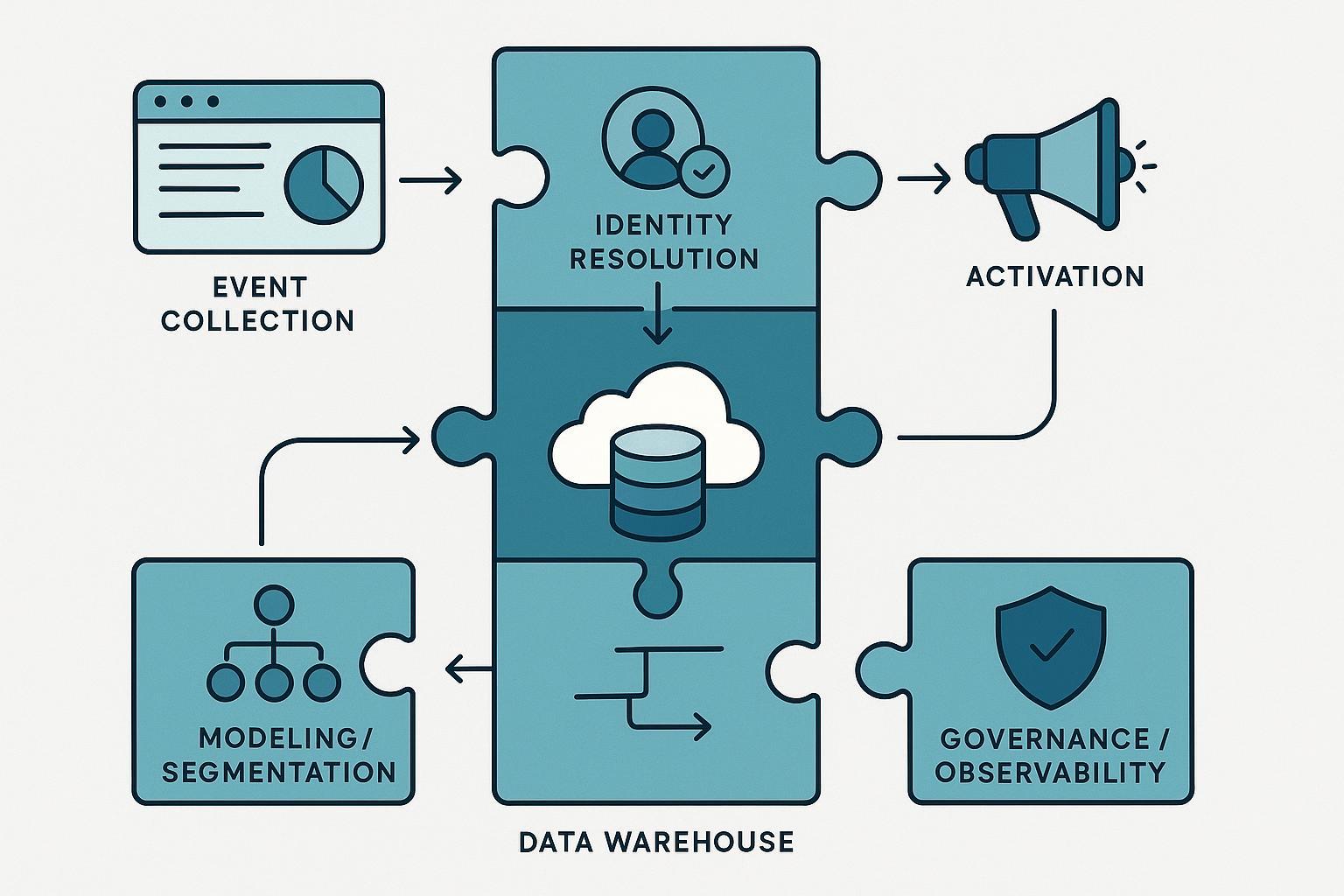
Architecture at a glance Think “choose‑your‑own‑stack” (composable) versus “appliance” (packaged). In a composable CDP, the warehouse/lakehouse is the system of record, surrounded by pluggable components.
[Sources] → [Ingestion/ETL/Streaming] → [Warehouse/Lakehouse]
Web/app events SaaS/DB CDC (System of Record)
├─ Identity & ID graph
├─ Modeling/Segments
├─ Consent & Governance
├─ Observability/Lineage
└─ Activation Views/Feeds
↓
[Destinations: Ads, Email/SMS, CRM, In‑app]
Deep‑dive: Components and data flows
- Collection and ingestion
- Event collection: Web, mobile, and server events stream into the warehouse/lakehouse via native streaming. Examples include Snowflake’s Snowpipe Streaming, Databricks Structured Streaming real‑time mode, and BigQuery’s Storage Write API streaming.
- Batch/CDC: Replicate SaaS and OLTP data (orders, CRM, tickets) with change data capture into your warehouse tables to complete behavioral + transactional context.
- Storage and transformation (system of record)
- The warehouse/lakehouse holds canonical customer, event, and relationship tables. Incremental processing and materializations power fresh segments without full reloads.
- Quality and contracts: Embed tests and CI around transformation code. The dbt community documents practices for layered models, testing, and semantic consistency—see dbt’s guide on how we structure projects.
- Identity and profile
- Identity resolution stitches first‑party identifiers (emails, user IDs, device IDs) and reconciles multi‑touch journeys. Approaches range from deterministic to probabilistic, often with entity relationships (e.g., person↔household or user↔account in B2B). The CDP Institute’s 2024 primer frames these as core CDP capabilities in both composable and packaged approaches—see the CDP Institute primer.
- Governed ID graphs: Keep consent and purpose flags alongside identifiers to ensure every downstream activation respects user choices and regional rules.
- Modeling, segmentation, and features
- Define reusable models for lifecycle stages, LTV, churn risk, and product usage with SQL or notebooks. Many teams converge CDP models with ML feature stores, enabling predictive audiences.
- Materialization for speed: Use incremental models, streaming tables, or materialized views as appropriate to refresh segments quickly.
- Activation and measurement
- Reverse ETL/audience sync pushes governed audience tables to ad platforms, email/SMS, CRM, and in‑app destinations. For streaming triggers, use native warehouse hooks or serverless functions.
- Zero‑copy/federated sharing: For some partners and internal domains, share governed views without copying data—Snowflake’s Secure Data Sharing and Databricks Delta Sharing illustrate patterns to keep data in place while controlling access.
- Governance, privacy, and observability
- Privacy‑by‑design: GDPR treats valid consent as “freely given, specific, informed, and unambiguous,” with proof and easy withdrawal—see the EDPB’s Guidelines on consent (2020).
- Enforce in the warehouse: Apply masking, row‑level policies, and tagging so only eligible users, segments, and destinations see PII. Snowflake documents Dynamic Data Masking and row access policies; BigQuery supports IAM and policy‑tag–based column controls.
- Reliability and lineage: Monitor data quality and job health; capture lineage for auditability. See OpenLineage’s community standard in the OpenLineage project and use validation frameworks like Great Expectations to enforce data contracts.
Latency and “real‑time” in 2025: what’s realistic?
- Warehouses now support low‑latency ingestion and incremental processing. But end‑to‑end activation includes destination API speeds and orchestration overhead.
- Databricks positions a real‑time mode for ultra‑low‑latency streaming workloads—see Structured Streaming real‑time mode.
- BigQuery cautions that exceeding 40–50 CreateWriteStream calls/sec can push call latency above 25 seconds (2023–2024 guidance). Takeaway: seconds‑to‑tens‑of‑seconds is common for warehouse‑native activation; sub‑second personalization usually requires edge decisioning and caching.
Composable vs. packaged CDP: a balanced comparison Advantages of composable
- Data control and governance: Keep PII in your environment with native policies and audits.
- Flexibility and extensibility: Model any entity (people, accounts, devices, subscriptions) and adapt quickly.
- Avoid lock‑in: Swap components independently and align costs to actual usage.
- Leverage existing investments: Use your warehouse, ELT, notebooks/ML, and observability stack.
Challenges of composable
- Integration complexity: You’re assembling and operating multiple pieces; design and ops maturity needed.
- Skill requirements: Data/analytics engineering, governance, and DevOps practices are prerequisites.
- Latency nuance: True sub‑second use cases may need edge systems in addition to the warehouse.
- Cost management: Streaming, materializations, and frequent syncs consume compute—visibility and budgets matter.
Where packaged CDPs may fit better
- Small teams needing turnkey UI and fast time‑to‑value.
- Limited data engineering capacity or minimal warehouse maturity.
- Standard retail/lifecycle use cases where out‑of‑the‑box connectors and builders suffice.
Decision levers
- Urgency vs. customization: Immediate campaigns and small teams → packaged; complex data models and strong data team → composable.
- Compliance posture: Strict residency/audits favor warehouse‑native control.
- Data complexity: Multi‑entity B2B, long histories, or custom touchpoints tilt toward composable.
- Cost horizon: Compare bundled MAU pricing vs. unbundled compute/egress over 12–36 months.
Three mini‑scenarios
- E‑commerce
- Data: Web/app events, orders, returns, support tickets.
- Flow: Events stream into warehouse; CDC brings orders. Identity stitches email↔device↔customer ID with consent flags. Segments like “high‑LTV, recent browsers with cart events” materialize every few minutes. Reverse ETL syncs to ads and ESP; on‑site personalization reads a governed view. Measurement closes the loop in the warehouse.
- B2B SaaS
- Data: Product usage events, CRM leads/contacts/accounts/opportunities, billing.
- Flow: Account‑based identity ties users↔accounts. Milestone models (activation, PQLs) drive lifecycle emails and sales alerts. Slack/CRM alerts trigger from change data in the warehouse; MAP receives audiences via scheduled syncs.
- Fintech
- Data: Transactions, KYC, risk scores, app telemetry.
- Flow: Strict consent and residency enforced via warehouse policies; risk models and marketing suppression lists share a common “eligibility” table. Marketing activation excludes users lacking consent; audits leverage lineage metadata.
Common pitfalls and how to avoid them
- Underrating identity complexity: Edge cases (shared devices, merged accounts) require careful rules and backfills. Keep auditable ID graph snapshots.
- Skipping data contracts: Without tests and SLAs, segments drift. Enforce column contracts and referential integrity with CI and validation tools.
- Ignoring latency and cost: Model refresh cadence and API limits; budget for streaming and frequent syncs.
- Re‑creating lock‑in: Even in a “composable” stack, avoid over‑committing to one vendor’s closed ecosystem without exit paths.
Quick FAQ
- Is a composable CDP just “warehouse + reverse ETL”? No. Activation is one component. Identity, consent/governance, and modeling are equally important.
- Can composable do real‑time? Warehouses can reach seconds to tens of seconds; for sub‑second experiences, pair with edge decisioning. Use streaming ingestion and incremental models to minimize lag; see Snowflake Snowpipe Streaming and Databricks real‑time mode.
- How do we enforce consent? Store consent states and purposes with profiles and apply policy‑based access in the warehouse. The EDPB’s consent guidelines (2020) outline requirements to meet before activating.
Get‑started checklist (30–90 days)
- Clarify use cases and latency targets: batch audiences vs. near‑real‑time triggers; channels and SLAs.
- Inventory data sources and identifiers; define the initial ID graph and consent schema.
- Stand up streaming/batch ingestion to your warehouse; pick one streaming path to harden.
- Establish modeling standards: naming, layered structure, tests, and CI (see dbt’s project structure guide).
- Implement governance controls on PII: masking/row policies and role‑based access (e.g., Snowflake Dynamic Data Masking).
- Create activation views with minimal columns; pilot one or two destinations via audience sync or APIs.
- Add observability: pipeline monitoring, cost dashboards, lineage capture (e.g., OpenLineage community).
- Prove value with one closed‑loop use case (trigger, activation, measurement) before broadening.
Key sources to explore next
- Analyst definition and contrasts: CDP Institute’s composable vs packaged primer (2024)
- Warehouse streaming and governance: Snowpipe Streaming, Databricks real‑time mode, BigQuery Storage Write API best practices
- Privacy and consent: EDPB’s Guidelines on consent (2020)
- Data contracts and lineage: Great Expectations docs, OpenLineage community
In short: A composable CDP lets you deliver CDP outcomes on your own governed data, trading turnkey convenience for control and flexibility. If you already invest in a modern warehouse and have data/analytics engineering maturity, it’s a compelling path—especially for complex models, strict compliance, or long‑term vendor flexibility.
