Bayesian MMM (MMM 2.0): A Plain‑English Guide to Modern Media Mix Modeling

If you’re hearing more about “Bayesian MMM” and “MMM 2.0,” you’re not alone. As identifiers disappear and privacy norms tighten, marketers need trustworthy, always-on measurement that doesn’t rely on user-level tracking. Apple’s App Tracking Transparency (rolled out widely in 2021) and Chrome’s ongoing phase‑out of third‑party cookies have accelerated this shift, as described in Apple’s own developer guidance on privacy and ATT and the Chromium team’s 2024 update on the third‑party cookie deprecation timeline (Apple, User Privacy and Data Use; Chromium Blog, Third‑party cookies 2024 update).
This guide defines Bayesian Marketing Mix Modeling (Bayesian MMM), clarifies how it relates to “MMM 2.0,” explains core modeling pieces in plain language, and highlights practical pitfalls and tools you can use today.
Quick definitions
- Bayesian Marketing Mix Modeling (Bayesian MMM): A media mix modeling approach estimated in a Bayesian framework. Instead of single point estimates, you infer full posterior distributions for parameters like channel ROAS, carryover (adstock), and saturation. This enables principled uncertainty intervals, incorporation of prior knowledge, and hierarchical pooling across brands/regions.
- MMM 2.0: The modern, privacy-resilient practice of MMM: always-on updates, explicit uncertainty reporting, non-linear response modeling (adstock and saturation), and calibration/validation using experiments (e.g., geo‑lifts). MMM 2.0 often uses Bayesian methods, but it doesn’t have to.
Relationship in one line: Most MMM 2.0 stacks are Bayesian, but not all; MMM 2.0 refers to the operating model and standards, while Bayesian MMM refers to the statistical estimation approach.
What it is not:
- Not multi‑touch attribution (MTA). MMM uses aggregated data (weekly by channel/region); MTA uses user‑level paths.
- Not a magic causal oracle. MMM needs exogenous variation and/or experimental calibration to strengthen causal claims.
Classical MMM vs Bayesian MMM vs MMM 2.0
- Estimates:
- Classical MMM: Point estimates with narrow or absent uncertainty communication.
- Bayesian MMM: Full posteriors and credible intervals by default.
- MMM 2.0: Requires uncertainty reporting and decisioning on marginal ROAS with intervals.
- Cadence:
- Classical: Periodic/quarterly, manual.
- Bayesian: Amenable to automation via priors and probabilistic programming.
- MMM 2.0: Always‑on refresh, versioned model governance.
- Non‑linearities:
- Classical: Often linear or ad‑hoc transforms.
- Bayesian: Native handling via priors and parameterized curves.
- MMM 2.0: Explicit adstock + saturation with diagnostics.
- Calibration/validation:
- Classical: Limited.
- Bayesian: Natural integration with experimental evidence via priors/likelihood.
- MMM 2.0: Requires geo-/lift‑experiments and out‑of‑sample tests.
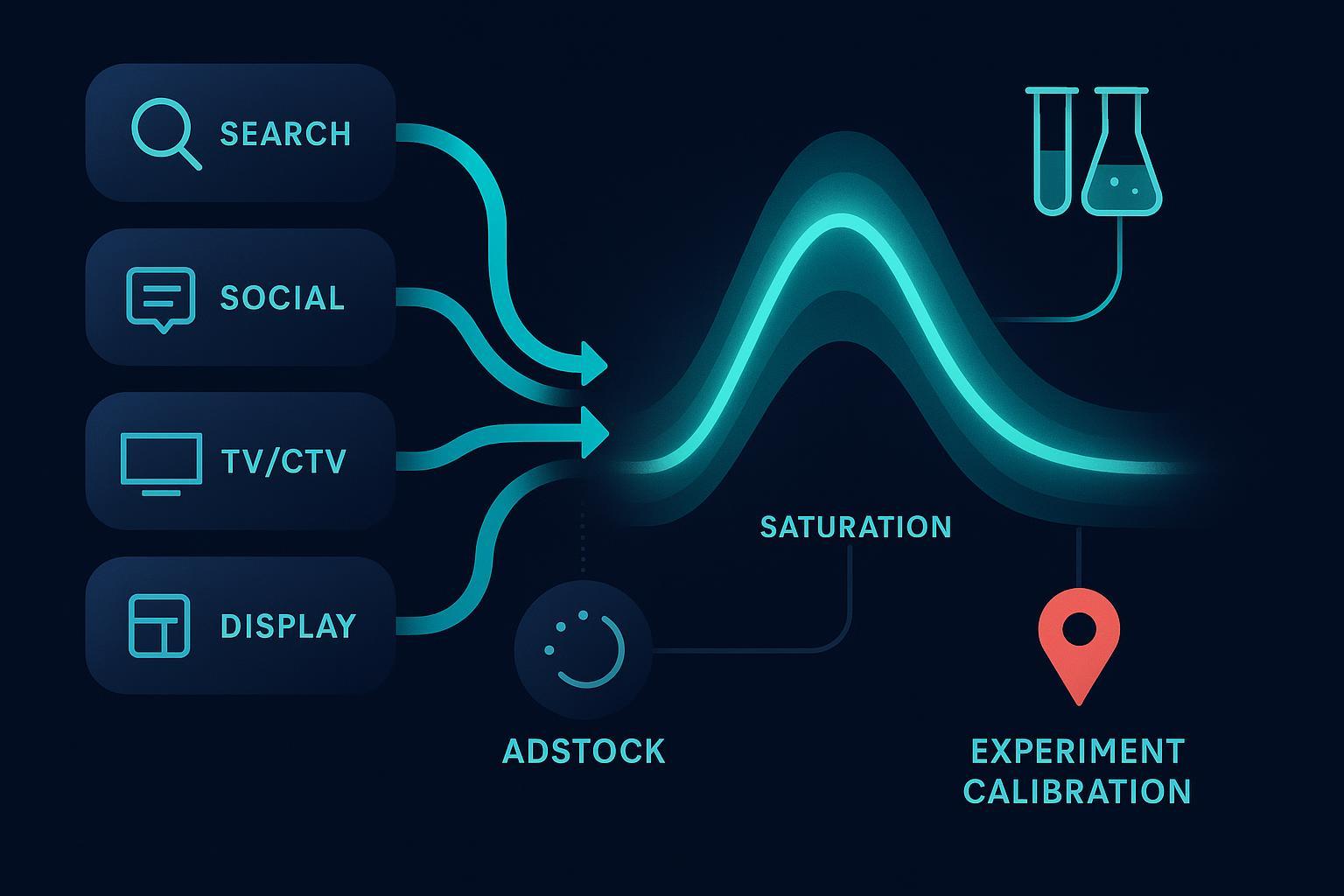
Core modeling pieces in plain English
- Adstock (carryover): Think of advertising like an echo in a canyon. After the spot airs or the ad runs, part of the effect lingers and fades over subsequent weeks. Models parameterize this “memory” with a decay rate (and sometimes a delayed peak). Practical result: a portion of this week’s impact actually shows up next week—and the week after—at diminishing strength. Google’s open‑source Bayesian library documents adstock transforms alongside non‑linear response curves in its README (Google Research, LightweightMMM).
- Saturation (diminishing returns): The first dollars you spend usually move the needle the most; as you keep spending, each extra dollar adds less. Models capture this with curves like the Hill function, producing response curves you can use to optimize budgets on marginal ROAS. Meta’s widely used open‑source MMM implements Hill saturation and multiple adstock families (Meta, Robyn GitHub).
- Baseline vs incremental: Baseline sales happen with no media (driven by seasonality, distribution, price, macro factors). Media adds incremental lift on top of that baseline.
- Priors and hierarchical pooling: Priors encode realistic ranges (e.g., ROAS non‑negative; adstock between 0 and 1). Hierarchical structures “share strength” across similar entities (e.g., regions or products), stabilizing noisy channels and improving generalization.
- Exogenous controls: Promotions, price/index, holidays/seasonality, macroeconomic indicators, and competitor proxies should be included to prevent media from soaking up unrelated variation.
Inference and diagnostics—without the math
- MCMC vs VI: Markov Chain Monte Carlo (MCMC) is the gold standard for accuracy but can be slower; variational inference (VI) scales faster but may understate uncertainty. In MMM 2.0, teams often start with MCMC for baseline models, then consider VI for frequent refreshes.
- Convergence checks: Two standard diagnostics—R‑hat close to 1.00 and adequate Effective Sample Size (ESS)—indicate chains have mixed well. The improved rank‑normalized R‑hat is described by the 2021 paper by Vehtari, Gelman, Simpson et al. (Vehtari et al., R‑hat improvements 2021). The broader Bayesian workflow—including prior/posterior predictive checks—is summarized by Gelman et al. (Gelman et al., Bayesian workflow 2020).
- Posterior predictive checks (PPCs): If your simulated data from the fitted model doesn’t look like reality (e.g., wrong seasonality amplitude or lag), the model likely needs re‑specification.
Validation and calibration with experiments
- Time‑series cross‑validation: Use rolling/blocked folds to evaluate out‑of‑sample performance without leaking future information. A practical overview for forecasters is provided in the 2021 edition of Hyndman & Athanasopoulos’s textbook (FPP3, time‑series CV).
- Geo‑ and lift‑experiments: Randomize spend across markets or holdout groups to estimate true incrementality, then use those estimates to calibrate your MMM. Meta maintains an open‑source framework for geo‑experimentation you can adapt or learn from (Meta, GeoLift GitHub).
- How calibration fits in: You can incorporate experimental lift as informative priors, as hard constraints, or as calibration targets in post‑processing to align MMM lift with experimental evidence.
Common pitfalls—and how to mitigate them
- Identifiability: When channels move together (e.g., Social and Display always scale simultaneously), the model can’t cleanly tell them apart.
- Mitigate with designed variation (geo/time splits), informative priors, hierarchical pooling, and experiment‑based calibration.
- Multicollinearity: Highly correlated inputs yield unstable estimates.
- Mitigate by grouping correlated subchannels, using regularization, dimensionality reduction, or orthogonalization where appropriate.
- Non‑stationarity and structural breaks: Platform changes or market shocks shift relationships.
- Mitigate with rolling refits, regime indicators, interaction terms, time‑varying parameters, and frequent re‑calibration.
- Lag/memory misspecification: Using the wrong adstock shape or ignoring delays creates biased effects.
- Mitigate by testing different adstock families (geometric, Weibull, delayed‑peak) and selecting via cross‑validation.
- Weak upper‑funnel signals: Brand and awareness effects are diffuse and slow‑burn.
- Mitigate with longer windows, brand lift proxies (organic search, direct traffic, brand surveys), hierarchical priors, and dedicated experiments.
- Ignoring non‑linearities: Linear models overstate ROI at scale.
- Mitigate by always modeling saturation, reporting response curves, and optimizing on marginal—not average—ROAS.
- Data quality: Missing, inconsistent, or mismatched granularity undermines inference.
- Mitigate with clear data contracts, QA checks, harmonized taxonomies, consistent weekly cadence, and enough history (ideally 2–3 years).
The 2025 tooling landscape (open‑source)
- Google Research—LightweightMMM (Bayesian): A canonical open‑source Bayesian MMM that ships adstock and saturation transforms, informative priors, and educational examples (Google Research, LightweightMMM).
- PyMC‑Marketing (Bayesian): A flexible Python library built on PyMC for MMM and demand models, well‑suited for custom priors, hierarchical structures, and transparent notebooks (PyMC‑Marketing documentation).
- Meta—Robyn (regularized frequentist, MMM 2.0‑compatible): An industry‑popular R package using ridge regression with adstock/saturation transforms, hyperparameter search, and strong automation; it also supports experimental calibration workflows (Meta, Robyn GitHub).
- Experimentation companion: For geo‑lifts and incrementality tests, many teams reference or adapt Meta’s open‑source framework (Meta, GeoLift GitHub).
Note: You may hear references to “Meridian.” At the time of writing, the widely adopted open‑source release from Google Research is LightweightMMM; if newer projects are announced, review their official documentation before adopting.
A concrete example (DTC brand)
Imagine a DTC e‑commerce brand investing in Paid Search, Paid Social, CTV, and Influencers across 8 regions.
- Data: 3 years of weekly data; include promotions, price/index, seasonality, macro indicators, and a competitor proxy.
- Model: Bayesian MMM with hierarchical priors across regions; delayed‑peak adstock for CTV; Hill saturation for each channel.
- Inference & checks: Fit with MCMC; confirm R‑hat ≈ 1 and adequate ESS; run posterior predictive checks to ensure seasonality and lags are realistic.
- Calibration: Quarterly 8‑market geo‑lifts on Social and CTV; feed the measured lift as informative priors or constraints.
- Decisioning: Produce response curves and marginal ROAS by channel. Reallocate next‑quarter budget toward channels with the highest marginal ROAS within capacity constraints, and report credible intervals so leaders can weigh risk.
- Operations: Update monthly; re‑run after major promos or platform changes.
How to get started (checklist)
- Define the decision: Allocation, forecasting, or planning? Pick the horizon and cadence.
- Standardize data: Weekly granularity, harmonized taxonomy, 2–3 years of history, consistent cost/revenue definitions.
- Model basics: Include adstock and saturation, a clean baseline (seasonality, promotions, macro), and priors with realistic bounds.
- Pick your stack: Start with a transparent open‑source option (LightweightMMM, PyMC‑Marketing, or Robyn). Pair with a geo‑lift framework for calibration.
- Run diagnostics: R‑hat, ESS, PPCs. If diagnostics fail, fix the model before shipping recommendations.
- Validate out of sample: Use time‑series cross‑validation and holdout periods.
- Calibrate: Integrate experiment lift as priors or targets; reconcile MMM with experiments.
- Communicate uncertainty: Share credible intervals, not just point ROAS. Optimize on marginal ROAS.
FAQ
- Is Bayesian MMM the same as MMM 2.0? No. Bayesian MMM is a statistical approach; MMM 2.0 is the modern operating model (always‑on, calibrated, uncertainty‑aware). Many MMM 2.0 implementations are Bayesian, but not all.
- Do I need experiments? If you want strong causal confidence, yes. Geo‑ or lift‑experiments provide gold‑standard incrementality estimates you can use to calibrate your MMM.
- How often should I refresh? Monthly is common; refresh after major promotions or platform changes, and re‑calibrate quarterly with experiments.
- What about MTA? Use MMM for strategic, cross‑channel allocation and long‑run effects; use experiments and platform diagnostics for tactical questions where appropriate.
By adopting Bayesian MMM within an MMM 2.0 operating model—complete with adstock, saturation, rigorous diagnostics, and experiment calibration—you can produce ROAS and incrementality estimates that leaders can actually trust.
